Synchronization
Linux kernel’s synchronization methods
- Atomic bit operations
- Bit set/unset/test operations are provided
- Atomic integer operations
- Resolve the race when execute ‘var++’, ‘var–’, etc.
- Spinlocks
- Wait in CPU, not yielding CPU
- Mutex / Semaphore
- Goes to sleep while awaiting to be awaken
Atomic bit operations
- Architecture independent atomic bit operations
/**
* set_bit - Atomically set a bit in memory
* @nr: the bit to set
* @addr: the address to start counting from
*/
void set_bit(int nr, volatile unsigned long *addr);
/**
* clear_bit - Clears a bit in memory
* @nr: Bit to clear
* @addr: Address to start counting from
*/
void clear_bit(int nr, volatile unsigned long *addr);
/**
* change_bit - Toggle a bit in memory
* @nr: Bit to change
* @addr: Address to start counting from
*/
void change_bit(int nr, volatile unsigned long *addr);
/**
* test_and_set_bit - Set a bit and return its old value
* @nr: Bit to set
* @addr: Address to count from
*/
int test_and_set_bit(int nr, volatile unsigned long *addr);
/**
* test_and_clear_bit - Clear a bit and return its old value
* @nr: Bit to clear
* @addr: Address to count from
*/
int test_and_clear_bit(int nr, volatile unsigned long *addr);
/**
* test_and_change_bit - Change a bit and return its old value
* @nr: Bit to change
* @addr: Address to count from
*/
int test_and_change_bit(int nr, volatile unsigned long *addr);
Atomic integer operations
- Providing atomic operations on increment and decrement on integer values.
#define ATOMIC_INIT(i)
int atomic_read(const atomic_t *v);
void atomic_set(atomic_t *v, int i);
void atomic_add(int i, atomic_t *v);
void atomic_sub(int i, atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);
void atomic_inc(atomic_t *v);
void atomic_dec(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_inc_and_test(atomic_t *v);
Semaphore
- When no one is holding the lock, it can continue to the next after taking the lock
- If it’s already taken by someone else, the requestor will go to sleep until holder wakes it up
- Original semaphore allows multiple holders by setting counter value bigger than 1
- In general, counter 1 is used
- As taking a lock is the operation of decreasing the value, the function name is ‘down…()’.
-
Releasing the lock is the operation of increasing the value, so, the function name is ‘up…()’.
- Taking a lock
/**
* down - acquire the semaphore
* @sem: the semaphore to be acquired
*
* Acquires the semaphore. If no more tasks are allowed to acquire the
* semaphore, calling this function will put the task to sleep until the
* semaphore is released.
*
* Use of this function is deprecated, please use down_interruptible() or
* down_killable() instead.
*/
void down(struct semaphore *sem);
/**
* down_interruptible - acquire the semaphore unless interrupted
* @sem: the semaphore to be acquired
*
* Attempts to acquire the semaphore. If no more tasks are allowed to
* acquire the semaphore, calling this function will put the task to sleep.
* If the sleep is interrupted by a signal, this function will return -EINTR.
* If the semaphore is successfully acquired, this function returns 0.
*/
int down_interruptible(struct semaphore *sem);
/**
* down_trylock - try to acquire the semaphore, without waiting
* @sem: the semaphore to be acquired
*
* Try to acquire the semaphore atomically. Returns 0 if the mutex has
* been acquired successfully or 1 if it it cannot be acquired.
*
* NOTE: This return value is inverted from both spin_trylock and
* mutex_trylock! Be careful about this when converting code.
*
* Unlike mutex_trylock, this function can be used from interrupt context,
* and the semaphore can be released by any task or interrupt.
*/
int down_trylock(struct semaphore *sem);
- Releasing a lock
/**
* up - release the semaphore
* @sem: the semaphore to release
*
* Release the semaphore. Unlike mutexes, up() may be called from any
* context and even by tasks which have never called down().
*/
void up(struct semaphore *sem);
- Defining and initializing
/* Please don't access any members of this structure directly */
struct semaphore {
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};
#define __SEMAPHORE_INITIALIZER(name, n);
void sema_init(struct semaphore *sem, int val);
- Example
- First module which owns semaphore
/* sema_mod1.c */
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/fs.h>
#include <linux/semaphore.h>
struct semaphore my_sem;
EXPORT_SYMBOL(my_sem);
int my_open(struct inode *inode, struct file *file) {
if (down_trylock(&my_sem)) {
printk("down_trylock error. my_sem.count : %d\n", my_sem.count);
up(&my_sem);
return 0;
}
printk("open is called. my_sem.count : %d\n", my_sem.count);
up(&my_sem);
return 0;
}
struct file_operations fops = {
.owner = THIS_MODULE,
.open = my_open,
};
int major_no = 0;
/*-----------------------*/
/* DECLARE_MUTEX(my_sem); */
int my_init(void) {
sema_init(&my_sem, 1);
int my_init(void) {
sema_init(&my_sem, 1);
printk("Init semaphore unlocked, count=%d\n", my_sem.count);
if (down_interruptible(&my_sem))
return -1;
printk("After down, count=%d\n", my_sem.count);
major_no = register_chrdev(0, "MYDEV", &fops);
return 0;
}
void my_exit(void) {
unregister_chrdev(major_no, "MYDEV");
up(&my_sem);
printk("Exiting with semaphore having count = %d\n", my_sem.count);
}
module_init(my_init);
module_exit(my_exit);
- Second module which is trying to take the lock
/* sema_mod2.c */
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/semaphore.h>
#include <linux/errno.h>
extern struct semaphore my_sem;
int my_init(void) {
printk("Module 2 semaphore count=%d\n", my_sem.count);
if (down_interruptible(&my_sem)) {
// if (down_trylock(&my_sem)) {
printk("Not loading module; failed\n");
return -EBUSY;
}
printk("Module 2 semaphore down() count = %d\n", my_sem.count);
return 0;
}
void my_exit(void) {
up(&my_sem);
printk("Module2 semaphore end count=%d\n", my_sem.count);
}
module_init(my_init);
module_exit(my_exit);
- Test result: second semaphore will be blocked
root@devel:Kernel$ insmod sema_mod1.ko
root@devel:Kernel$ tail -n 2 /var/log/messages
Sep 27 15:33:38 devel kernel: Init semaphore unlocked, count=1
Sep 27 15:33:38 devel kernel: After down, count=0
root@devel:Kernel$ insmod sema_mod2.ko
### checking from the other terminal shows it's in 'S' state
dkwon@devel:Desktop$ ps aux | grep insmod | grep -v grep
root 13461 0.0 0.0 13152 748 pts/0 S+ 15:34 0:00 insmod sema_mod2.ko
root@devel:~$ cat /proc/13461/stack
[<ffffffff810ab95b>] down_interruptible+0x4b/0x60
[<ffffffffa06ae02a>] init_module+0x2a/0x70 [sema_mod2]
[<ffffffff810020e8>] do_one_initcall+0xb8/0x230
[<ffffffff810ed58e>] load_module+0x134e/0x1b50
[<ffffffff810edf46>] SyS_finit_module+0xa6/0xd0
[<ffffffff81645e89>] system_call_fastpath+0x16/0x1b
[<ffffffffffffffff>] 0xffffffffffffffff
Read/Write Semaphore
- Lock is mainly useful when there’s a modification (write) operation from multiple locations. If you are not serialize this multiple write requests, it can cause of inconsistency
- There are situations the critical area is mainly referred without modifying it (reader) and rarerly do some modifications (writer)
- If there are 9 readers and 1 writers, the time it takes to finish all will be sum of each operations even in the SMP environment
- If we are allowing 9 readers to run all together as they are not modifying the data, it will reduce the time to the longest operation of those 10 operations which will be much shorter than the normal lock operations.
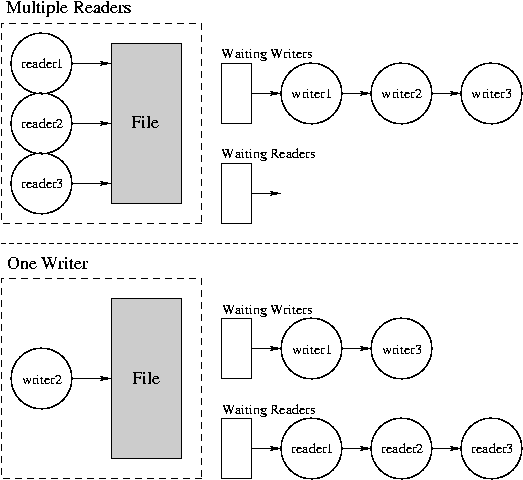
- A possible situation
- A reader requests a lock
- If no one is using it or only readers are using it, it’ll be granted
- If a writer is using it, it will be blocked
- If readers are using it and one or more writers are awaiting the lock, it will be blocked
- A writer requests a lock
- If no one is using it, it’ll be granted
- Otherwise, will be blocked
- A reader requests a lock
- There’s reader/writer version of semaphore defined in “<linux/rwsem.h>”
struct rw_semaphore {
rwsem_count_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
- Initialization can be done statically or dynamically
Staticial initialization
static DECLARE_RWSEM(name);
Dynamical initialization
init_rwsem(struct rw_semaphore *sem);
- Locking/Unlocking
/*
* lock for reading
*/
void __sched down_read(struct rw_semaphore *sem);
/*
* trylock for reading -- returns 1 if successful, 0 if contention
*/
int down_read_trylock(struct rw_semaphore *sem);
/*
* lock for writing
*/
void __sched down_write(struct rw_semaphore *sem);
/*
* trylock for writing -- returns 1 if successful, 0 if contention
*/
int down_write_trylock(struct rw_semaphore *sem);
/*
* release a read lock
*/
void up_read(struct rw_semaphore *sem);
/*
* release a write lock
*/
void up_write(struct rw_semaphore *sem);
/*
* downgrade write lock to read lock
*/
void downgrade_write(struct rw_semaphore *sem);
- Example
asmlinkage int sys_uname(struct old_utsname __user *name)
{
int err;
if (!name)
return -EFAULT;
down_read(&uts_sem);
err = copy_to_user(name, utsname(), sizeof(*name));
up_read(&uts_sem);
return err? -EFAULT:0;
}
SYSCALL_DEFINE2(sethostname, char __user *, name, int, len)
{
int errno;
char tmp[__NEW_UTS_LEN];
if (!capable(CAP_SYS_ADMIN))
return -EPERM;
if (len < 0 || len > __NEW_UTS_LEN)
return -EINVAL;
down_write(&uts_sem);
errno = -EFAULT;
if (!copy_from_user(tmp, name, len)) {
struct new_utsname *u = utsname();
memcpy(u->nodename, tmp, len);
memset(u->nodename + len, 0, sizeof(u->nodename) - len);
errno = 0;
}
up_write(&uts_sem);
return errno;
}
read/write semaphore case
crash> ps -m | grep UN | tail
[ 0 06:03:45.391] [UN] PID: 14236 TASK: ffff8801384d5500 CPU: 2 COMMAND: "java"
[ 0 06:03:45.391] [UN] PID: 14231 TASK: ffff88013a454040 CPU: 0 COMMAND: "java"
[ 0 17:41:42.383] [UN] PID: 37352 TASK: ffff880037b22ae0 CPU: 0 COMMAND: "python"
[ 0 22:35:27.497] [UN] PID: 14947 TASK: ffff8801386a0aa0 CPU: 1 COMMAND: "java"
[ 0 22:35:59.136] [UN] PID: 61 TASK: ffff880138f93540 CPU: 0 COMMAND: "khugepaged"
[ 0 22:36:45.400] [UN] PID: 2548 TASK: ffff8801384b7500 CPU: 1 COMMAND: "cmahostd"
[ 0 22:36:53.605] [UN] PID: 14244 TASK: ffff88008595b540 CPU: 2 COMMAND: "java"
[ 0 22:36:58.596] [UN] PID: 14955 TASK: ffff88001eba4ae0 CPU: 2 COMMAND: "java"
[ 0 22:36:58.596] [UN] PID: 53138 TASK: ffff88001d0b0080 CPU: 2 COMMAND: "java"
[ 0 22:36:58.601] [UN] PID: 14237 TASK: ffff88001ea2b500 CPU: 2 COMMAND: "java"
crash> bt 14237
PID: 14237 TASK: ffff88001ea2b500 CPU: 2 COMMAND: "java"
#0 [ffff88010b1dbd58] schedule at ffffffff815293c0
#1 [ffff88010b1dbe20] rwsem_down_failed_common at ffffffff8152ba85
#2 [ffff88010b1dbe80] rwsem_down_write_failed at ffffffff8152bbe3
#3 [ffff88010b1dbec0] call_rwsem_down_write_failed at ffffffff8128f503
#4 [ffff88010b1dbf20] sys_mprotect at ffffffff811520f6
#5 [ffff88010b1dbf80] system_call_fastpath at ffffffff8100b072
RIP: 0000003e7d0e52a7 RSP: 00007fac2998ea90 RFLAGS: 00000206
RAX: 000000000000000a RBX: ffffffff8100b072 RCX: 0000000000000000
RDX: 0000000000000001 RSI: 0000000000001000 RDI: 00007fac2be3e000
RBP: 00007fac2998eb00 R8: fffffffffffff000 R9: 0000000000001000
R10: 00007fac2bb9ae70 R11: 0000000000000206 R12: 00007fac2bbad938
R13: 00007fac2bbb325c R14: 0000000000001000 R15: 0000000000000001
ORIG_RAX: 000000000000000a CS: 0033 SS: 002b
- Check which rw_semaphore it was tried to get
- %rdx had rw_semaphore value when it called rwsem_down_failed_common() which is saved in stack
crash> dis -lr ffffffff8152bbe3 | tail -n 11
0xffffffff8152bbcc <rwsem_down_write_failed+12>: mov %rdi,%rbx
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 211
0xffffffff8152bbcf <rwsem_down_write_failed+15>: lea -0x30(%rbp),%rsi
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 207
0xffffffff8152bbd3 <rwsem_down_write_failed+19>: sub $0x28,%rsp
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 210
0xffffffff8152bbd7 <rwsem_down_write_failed+23>: movl $0x2,-0x18(%rbp)
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 211
0xffffffff8152bbde <rwsem_down_write_failed+30>: callq 0xffffffff8152b9f0 <rwsem_down_failed_common>
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 214
0xffffffff8152bbe3 <rwsem_down_write_failed+35>: mov %rbx,%rax
crash> dis -lr ffffffff8152ba85 | head -n 16
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 153
0xffffffff8152b9f0 <rwsem_down_failed_common>: push %rbp
0xffffffff8152b9f1 <rwsem_down_failed_common+1>: mov %rdx,%rax
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/arch/x86/include/asm/cmpxchg_64.h: 46
0xffffffff8152b9f4 <rwsem_down_failed_common+4>: mov $0x2,%edx
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 153
0xffffffff8152b9f9 <rwsem_down_failed_common+9>: mov %rsp,%rbp
0xffffffff8152b9fc <rwsem_down_failed_common+12>: push %r15
0xffffffff8152b9fe <rwsem_down_failed_common+14>: push %r14
0xffffffff8152ba00 <rwsem_down_failed_common+16>: push %r13
0xffffffff8152ba02 <rwsem_down_failed_common+18>: mov %rsi,%r13
0xffffffff8152ba05 <rwsem_down_failed_common+21>: push %r12
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/arch/x86/include/asm/current.h: 14
0xffffffff8152ba07 <rwsem_down_failed_common+23>: mov %gs:0xbbc0,%r12
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/lib/rwsem.c: 153
0xffffffff8152ba10 <rwsem_down_failed_common+32>: push %rbx
crash> bt -f | grep ' rwsem_down_write_failed' -B 4
ffff88010b1dbe48: ffff880004000001 ffff8800355f0c28
^
+--- push %rbx
ffff88010b1dbe58: 00007fac2be3f000 0000000000000001
ffff88010b1dbe68: 0000000000000000 0000000000000005
ffff88010b1dbe78: ffff88010b1dbeb8 ffffffff8152bbe3
#2 [ffff88010b1dbe80] rwsem_down_write_failed at ffffffff8152bbe3
- This is the semaphore which is called from the below.
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/mm/mprotect.c: 284
0xffffffff811520e2 <sys_mprotect+210>: mov 0x480(%rbx),%rdi
0xffffffff811520e9 <sys_mprotect+217>: mov %rcx,-0x50(%rbp)
0xffffffff811520ed <sys_mprotect+221>: add $0x68,%rdi
0xffffffff811520f1 <sys_mprotect+225>: callq 0xffffffff8152b0b0 <down_write>
crash> task_struct.mm ffff88001ea2b500
mm = 0xffff8800355f0bc0
crash> mm_struct.mmap_sem 0xffff8800355f0bc0
mmap_sem = {
count = -270582939646,
wait_lock = {
raw_lock = {
slock = 3994283539
}
},
wait_list = {
next = 0xffff88010b1dbe88,
prev = 0xffff88001fd4bcc0
}
}
282 vm_flags = calc_vm_prot_bits(prot);
283
284 down_write(¤t->mm->mmap_sem);
crash> mm_struct.mmap_sem 0xffff8800355f0bc0 -ox
struct mm_struct {
[ffff8800355f0c28] struct rw_semaphore mmap_sem;
}
- Checking who is using this semaphore or want to use it can be checked with crashinfo extension
crash> crashinfo --rwsemaphore=0xffff8800355f0c28
<struct rw_semaphore 0xffff8800355f0c28>
61 khugepaged
2548 cmahostd
9822 java
10500 python
10961 ps
10967 ps
11968 ps
13002 ps
13497 ps
13611 java
14000 ps
14231 java
14232 java
14233 java
14234 java
14235 java
14236 java
14237 java
14238 java
14239 java
14240 java
14241 java
14242 java
14243 java
14244 java
14936 java
14945 java
14946 java
14947 java
14948 java
14953 java
14954 java
14955 java
14956 java
14957 java
14958 java
14959 java
14962 java
14964 java
14971 java
14974 java
14975 java
14981 java
16394 java
16395 java
16396 java
16397 java
16398 java
16925 java
17417 java
18742 java
25835 ps
27426 python
37352 python
39015 ps
53138 java
59185 java
61820 ps
62428 java
62638 ps
62864 python
64424 ps
64932 ps
** Execution took 0.05s (real) 0.04s (CPU)
- There are quite lots of processes involved in this rw_semaphore.
- Checking each ‘bt’ shows that most of them were failed in using this semaphore and in sleep except two process - Process 53138 and 14955.
crash> bt 53138
PID: 53138 TASK: ffff88001d0b0080 CPU: 2 COMMAND: "java"
#0 [ffff8801109257d0] schedule at ffffffff815293c0
#1 [ffff880110925898] rwsem_down_failed_common at ffffffff8152ba85
#2 [ffff8801109258f8] rwsem_down_read_failed at ffffffff8152bc16
#3 [ffff880110925938] call_rwsem_down_read_failed at ffffffff8128f4d4
#4 [ffff8801109259a0] __do_page_fault at ffffffff8104a92e
#5 [ffff880110925ac0] do_page_fault at ffffffff8152ef5e
#6 [ffff880110925af0] page_fault at ffffffff8152c315
[exception RIP: copy_user_enhanced_fast_string+6]
RIP: ffffffff8128e0d6 RSP: ffff880110925ba0 RFLAGS: 00010202
RAX: ffff880110924000 RBX: ffff88013b78a480 RCX: 0000000000002fd2
RDX: 0000000000003aa8 RSI: 00007fff90c1c000 RDI: ffff88001a794ad6
RBP: ffff880110925bc8 R8: 0000000000000246 R9: 0000000000000000
R10: 0000000000000002 R11: 0000000000000000 R12: ffff8800355f0bc0
R13: ffff8800355f0c28 R14: ffff88001d0b0878 R15: ffff88008592e328
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0000
#7 [ffff880110925ba0] newLinuxThreadInfo at ffffffffa0328ccd [talpa_linux]
#8 [ffff880110925bd0] newThreadInfo at ffffffffa032891e [talpa_linux]
#9 [ffff880110925be0] examineFile at ffffffffa0379a19 [talpa_core]
#10 [ffff880110925c90] examineFileInfo at ffffffffa0373a43 [talpa_core]
#11 [ffff880110925ce0] talpaOpen at ffffffffa035f176 [talpa_vfshook]
#12 [ffff880110925d30] __dentry_open at ffffffff81185e3a
#13 [ffff880110925d90] nameidata_to_filp at ffffffff811861a4
#14 [ffff880110925db0] do_filp_open at ffffffff8119be90
#15 [ffff880110925f20] do_sys_open at ffffffff81185be9
#16 [ffff880110925f70] sys_open at ffffffff81185d00
#17 [ffff880110925f80] system_call_fastpath at ffffffff8100b072
RIP: 0000003e7d40ef9d RSP: 00007fab9fcfaa30 RFLAGS: 00010202
RAX: 0000000000000002 RBX: ffffffff8100b072 RCX: 0000000000000280
RDX: 00000000000001b6 RSI: 0000000000000000 RDI: 00007fabb02ea910
RBP: 00007fab9fcfaa10 R8: 00007fabb02ea910 R9: 00007fac2bbaf3b8
R10: 00007fac2bbb3258 R11: 0000000000000293 R12: ffffffff81185d00
R13: ffff880110925f78 R14: 00007fab9fcfab18 R15: 0000000000000000
ORIG_RAX: 0000000000000002 CS: 0033 SS: 002b
- It looks like dealing with rw_semaphore, but let’s dig in.
- By disassembling ‘newLinuxThreadInfo()’ even without source code, we can tell it’s using ‘down_read_trylock()’.
crash> dis -lr ffffffffa0328ccd | tail -n 18
0xffffffffa0328c81 <newLinuxThreadInfo+305>: lea 0x68(%r12),%r13
0xffffffffa0328c86 <newLinuxThreadInfo+310>: mov %r13,%rdi
0xffffffffa0328c89 <newLinuxThreadInfo+313>: callq 0xffffffff810a03e0 <down_read_trylock>
...
0xffffffffa0328cb9 <newLinuxThreadInfo+361>: mov 0x60(%rbx),%rdx
0xffffffffa0328cbd <newLinuxThreadInfo+365>: mov 0x150(%r12),%rsi
0xffffffffa0328cc5 <newLinuxThreadInfo+373>: mov %rax,%rdi
0xffffffffa0328cc8 <newLinuxThreadInfo+376>: callq 0xffffffff8128dfb0 <copy_from_user>
- The argument was from %r13 which was from 0x68(%r12) and this %r12 was still same until it called ‘copy_from_user()’.
- Below is confirming it’s not touching %r12 yet.
crash> dis -lr copy_user_enhanced_fast_string+6
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/arch/x86/lib/copy_user_64.S: 284
0xffffffff8128e0d0 <copy_user_enhanced_fast_string>: and %edx,%edx
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/arch/x86/lib/copy_user_64.S: 285
0xffffffff8128e0d2 <copy_user_enhanced_fast_string+2>: je 0xffffffff8128e0d8 <copy_user_enhanced_fast_string+8>
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/arch/x86/lib/copy_user_64.S: 286
0xffffffff8128e0d4 <copy_user_enhanced_fast_string+4>: mov %edx,%ecx
/usr/src/debug/kernel-2.6.32-431.46.2.el6/linux-2.6.32-431.46.2.el6.x86_64/arch/x86/lib/copy_user_64.S: 287
0xffffffff8128e0d6 <copy_user_enhanced_fast_string+6>: rep movsb %ds:(%rsi),%es:(%rdi)
- %r12 had the below value and 0x68(%r12) had the value others were looking for.
R12: ffff8800355f0bc0
crash> px 0xffff8800355f0bc0+0x68
$5 = 0xffff8800355f0c28
-
As these processes are already in using of rw_semaphore as readers, other writer operations couldn’t get in.
-
Interestingly, this process is also awaiting for the same semaphore
#1 [ffff880110925898] rwsem_down_failed_common at ffffffff8152ba85
ffff8801109258a0: 0000000000000000 0000000001000000
ffff8801109258b0: ffff88002be533c0 fffffffeffffffff
ffff8801109258c0: ffff88002be55840 ffff8800355f0c28
^
+--- rw_semphoare
ffff8801109258d0: 00007fff90c1c000 ffff8800355f0bc0
ffff8801109258e0: 0000000000000400 0000000000000000
ffff8801109258f0: ffff880110925930 ffffffff8152bc16
#2 [ffff8801109258f8] rwsem_down_read_failed at ffffffff8152bc16
- This function ‘newLInuxThreadInfo()’ in talpa_linux causes of deadlock situation by holding this lock and went to sleep to get the same lock
Mutex lock
- It’s a semaphore with count 1 which means can be locked by only one at once
- only one task can hold the mutex at a time
- only the owner can unlock the mutex
- multiple unlocks are not permitted
- recursive locking is not permitted
- a mutex object must be initialized via the API
- a mutex object must not be initialized via memset or copying
- task may not exit with mutex held
- memory areas where held locks reside must not be freed
- held mutexes must not be reinitialized
- mutexes may not be used in hardware or software interrupt contexts such as tasklets and timers
- It’s defined in <linux/mutex.h>
struct mutex;
mutex_init(mutex);
DEFINE_MUTEX(mutexname);
/**
* mutex_is_locked - is the mutex locked
* @lock: the mutex to be queried
*
* Returns 1 if the mutex is locked, 0 if unlocked.
*/
static inline int mutex_is_locked(struct mutex *lock);
/***
* mutex_lock - acquire the mutex
* @lock: the mutex to be acquired
*
* Lock the mutex exclusively for this task. If the mutex is not
* available right now, it will sleep until it can get it.
*
* The mutex must later on be released by the same task that
* acquired it. Recursive locking is not allowed. The task
* may not exit without first unlocking the mutex. Also, kernel
* memory where the mutex resides mutex must not be freed with
* the mutex still locked. The mutex must first be initialized
* (or statically defined) before it can be locked. memset()-ing
* the mutex to 0 is not allowed.
*
* ( The CONFIG_DEBUG_MUTEXES .config option turns on debugging
* checks that will enforce the restrictions and will also do
* deadlock debugging. )
*
* This function is similar to (but not equivalent to) down().
*/
void mutex_lock(struct mutex *lock);
int __must_check mutex_lock_interruptible(struct mutex *lock);
int __must_check mutex_lock_killable(struct mutex *lock);
/*
* NOTE: mutex_trylock() follows the spin_trylock() convention,
* not the down_trylock() convention!
*
* Returns 1 if the mutex has been acquired successfully, and 0 on contention.
*/
int mutex_trylock(struct mutex *lock);
/***
* mutex_unlock - release the mutex
* @lock: the mutex to be released
*
* Unlock a mutex that has been locked by this task previously.
*
* This function must not be used in interrupt context. Unlocking
* of a not locked mutex is not allowed.
*
* This function is similar to (but not equivalent to) up().
*/
void mutex_unlock(struct mutex *lock);
- Example
static DEFINE_MUTEX(sysdev_drivers_lock);
...
int sysdev_driver_register(struct sysdev_class *cls, struct sysdev_driver *drv)
{
...
mutex_lock(&sysdev_drivers_lock);
if (cls && kset_get(&cls->kset)) {
list_add_tail(&drv->entry, &cls->drivers);
/* If devices of this class already exist, tell the driver */
if (drv->add) {
struct sys_device *dev;
list_for_each_entry(dev, &cls->kset.list, kobj.entry)
drv->add(dev);
}
} else {
err = -EINVAL;
WARN(1, KERN_ERR "%s: invalid device class\n", __func__);
}
mutex_unlock(&sysdev_drivers_lock);
...
}
Spinlock
- semaphore makes the process goes into sleep and wakes up later once the condition is fullfiled. However, if the lock holding time is really short, this semaphore operation can be an overkill as it’ll takes sometime to wake it up and give it a CPU to run the next operation
- For a very short period of locking, kernel introduced ‘spin_lock’ which does not go to sleep and spinning in the CPU until other part is releasing it.
- Big difference from other locking mechanisms
- Shouldn’t go to sleep while holding the lock
- it’s best to have locking/unlocking in the same function level
- Period should be short enough, otherwise, you’ll see softlockup/hardlockup messages
- Pseudo code for spin_lock and spin_unlock from https://en.wikipedia.org/wiki/Spinlock
; Intel syntax
locked: ; The lock variable. 1 = locked, 0 = unlocked.
dd 0
spin_lock:
mov eax, 1 ; Set the EAX register to 1.
xchg eax, [locked] ; Atomically swap the EAX register with
; the lock variable.
; This will always store 1 to the lock, leaving
; the previous value in the EAX register.
test eax, eax ; Test EAX with itself. Among other things, this will
; set the processor's Zero Flag if EAX is 0.
; If EAX is 0, then the lock was unlocked and
; we just locked it.
; Otherwise, EAX is 1 and we didn't acquire the lock.
jnz spin_lock ; Jump back to the MOV instruction if the Zero Flag is
; not set; the lock was previously locked, and so
; we need to spin until it becomes unlocked.
ret ; The lock has been acquired, return to the calling
; function.
spin_unlock:
mov eax, 0 ; Set the EAX register to 0.
xchg eax, [locked] ; Atomically swap the EAX register with
; the lock variable.
ret ; The lock has been released.
- Real implementation in RHEL6
static __always_inline void __ticket_spin_lock(raw_spinlock_t *lock)
{
short inc;
asm volatile (
"1:\t\n"
"mov $0x100, %0\n\t"
LOCK_PREFIX "xaddw %w0, %1\n"
"2:\t"
"cmpb %h0, %b0\n\t"
"je 4f\n\t"
"3:\t\n"
"rep ; nop\n\t"
ALTERNATIVE(
"movb %1, %b0\n\t"
/* don't need lfence here, because loads are in-order */
"jmp 2b\n",
"", X86_FEATURE_UNFAIR_SPINLOCK)"\n\t"
"cmpw $0, %1\n\t"
"jne 3b\n\t"
"jmp 1b\n\t"
"4:"
: "=Q" (inc), "+m" (lock->slock)
:
: "memory", "cc");
}
static __always_inline void __ticket_spin_unlock(raw_spinlock_t *lock)
{
asm volatile(
ALTERNATIVE(UNLOCK_LOCK_PREFIX"incb (%0);"ASM_NOP3,
UNLOCK_LOCK_ALT_PREFIX"movw $0, (%0)",
X86_FEATURE_UNFAIR_SPINLOCK)
:
: "Q" (&lock->slock)
: "memory", "cc");
}
- Major structure and functions
typedef struct {
...
} spinlock_t;
/* Initialize the lock */
void spin_lock_init(lock) ;
/* Take the lock. If it's already taken, it'll be spin in the current CPU */
void spin_lock(spinlock_t *lock);
/* Release the lock */
void spin_unlock(spinlock_t *lock);
/* Take a lock and return 1. Otherwise, it'll return 0 */
int spin_trylock(spinlock_t *lock);
/* Check whether the lock is already taken.
return 0 if it's unlocked.
otherwise return true(1) */
int spin_is_locked(spinlock_t *lock);
/* Take a lock and disable the interrupt on the current CPU
Old interrupt state is saved in 'flags' */
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
/* Release the lock and restore the interrupt state based on the 'flags' */
void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags);
Read/Write spinlock
- Spinlock version of reader/writer support
- Multiple readers can run simultaneously
void read_lock(rwlock_t *lock);
int read_trylock(rwlock_t *lock);
void read_unlock(rwlock_t *lock);
void write_lock(rwlock_t *lock);
int write_trylock(rwlock_t *lock);
void write_unlock(rwlock_t *lock);
unsigned long read_lock_irqsave(rwlock_t *lock);
void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
unsigned long write_lock_irqsave(rwlock_t *lock);
void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
Big Kernel Lock
- Very old lock mechanism
- Large coarse grained lock which means it’s not implemented to target a specific role, so can be used in various location and that causes of big delay amont unrelated operations
- Not recommended to use.
- Obsolete and in the process of removing using this lock, but just takes time
/*
* Getting the big kernel lock.
*
* This cannot happen asynchronously, so we only need to
* worry about other CPU's.
*/
void lock_kernel(void);
void unlock_kernel(void);
- Examples
drivers/char/hpet.c
static int hpet_open(struct inode *inode, struct file *file)
{
...
lock_kernel();
...
unlock_kernel();
...
}
drivers/char/tty_io.c
static int tty_open(struct inode *inode, struct file *filp)
{
...
lock_kernel();
ret = __tty_open(inode, filp);
unlock_kernel();
return ret;
}
fs/ext4/super.c
static void ext4_put_super(struct super_block *sb)
{
...
lock_kernel();
...
unlock_kernel();
...
}
sound/core/sound.c
static int snd_open(struct inode *inode, struct file *file)
{
int ret;
lock_kernel();
ret = __snd_open(inode, file);
unlock_kernel();
return ret;
}
Completion
- It’s not a race among multiple threads, but it’s useful in producer/consumer situation
- It can be used when you need to wait until other part to be completed
- Data structure and declaration/initialization macros
/**
* struct completion - structure used to maintain state for a "completion"
*
* This is the opaque structure used to maintain the state for a "completion".
* Completions currently use a FIFO to queue threads that have to wait for
* the "completion" event.
*
* See also: complete(), wait_for_completion() (and friends _timeout,
* _interruptible, _interruptible_timeout, and _killable), init_completion(),
* and macros DECLARE_COMPLETION(), DECLARE_COMPLETION_ONSTACK(), and
* INIT_COMPLETION().
*/
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
/**
* DECLARE_COMPLETION: - declare and initialize a completion structure
* @work: identifier for the completion structure
*
* This macro declares and initializes a completion structure. Generally used
* for static declarations. You should use the _ONSTACK variant for automatic
* variables.
*/
#define DECLARE_COMPLETION(work) \
struct completion work = COMPLETION_INITIALIZER(work)
- Functions to initialize and use
/**
* init_completion: - Initialize a dynamically allocated completion
* @x: completion structure that is to be initialized
*
* This inline function will initialize a dynamically created completion
* structure.
*/
static inline void init_completion(struct completion *x);
/**
* wait_for_completion: - waits for completion of a task
* @x: holds the state of this particular completion
*
* This waits to be signaled for completion of a specific task. It is NOT
* interruptible and there is no timeout.
*
* See also similar routines (i.e. wait_for_completion_timeout()) with timeout
* and interrupt capability. Also see complete().
*/
void __sched wait_for_completion(struct completion *x);
/**
* wait_for_completion_timeout: - waits for completion of a task (w/timeout)
* @x: holds the state of this particular completion
* @timeout: timeout value in jiffies
*
* This waits for either a completion of a specific task to be signaled or for a
* specified timeout to expire. The timeout is in jiffies. It is not
* interruptible.
*/
unsigned long __sched
wait_for_completion_timeout(struct completion *x, unsigned long timeout);
/**
* wait_for_completion_interruptible: - waits for completion of a task (w/intr)
* @x: holds the state of this particular completion
*
* This waits for completion of a specific task to be signaled. It is
* interruptible.
*/
int __sched wait_for_completion_interruptible(struct completion *x);
unsigned long __sched
wait_for_completion_interruptible_timeout(struct completion *x,
unsigned long timeout);
/**
* complete: - signals a single thread waiting on this completion
* @x: holds the state of this particular completion
*
* This will wake up a single thread waiting on this completion. Threads will be
* awakened in the same order in which they were queued.
*
* See also complete_all(), wait_for_completion() and related routines.
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void complete(struct completion *x);
/**
* complete_all: - signals all threads waiting on this completion
* @x: holds the state of this particular completion
*
* This will wake up all threads waiting on this particular completion event.
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void complete_all(struct completion *x);
- Example : vfork
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
...
if (!IS_ERR(p)) {
struct completion vfork;
...
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
}
...
if (clone_flags & CLONE_VFORK) {
freezer_do_not_count();
wait_for_completion(&vfork);
freezer_count();
tracehook_report_vfork_done(p, nr);
}
...
}
void mm_release(struct task_struct *tsk, struct mm_struct *mm)
{
...
/* notify parent sleeping on vfork() */
if (vfork_done) {
tsk->vfork_done = NULL;
complete(vfork_done);
}
...
}
sequential lock
- read happens a lot with small number of write
-
It’ll give higher priority to writers
- Data structure
typedef struct {
unsigned sequence;
spinlock_t lock;
} seqlock_t;
- Initialization
void seqlock_init(seqlock_t *s);
DEFINE_SEQLOCK(name);
- Writer lock/unlock: Only one writer can run at one moment regardless of how many readers are running
void write_seqlock(seqlock_t *sl);
void write_sequnlock(seqlock_t *sl);
- It doesn’t checking if writer is running, but at the end check if there’s any modification
- If there’s writer during this block, it’ll re-run the whole loop (discard the earlier result)
unsigned read_seqbegin(const seqlock_t *sl);
int read_seqretry(const seqlock_t *sl, unsigned iv);
- Example
void xtime_update(unsigned long ticks)
{
write_seqlock(&xtime_lock);
do_timer(ticks);
write_sequnlock(&xtime_lock);
}
u64 get_jiffies_64(void)
{
unsigned long seq;
u64 ret;
do {
seq = read_seqbegin(&xtime_lock);
ret = jiffies_64;
} while (read_seqretry(&xtime_lock, seq));
return ret;
}
RCU (Read-copy-update)
https://en.wikipedia.org/wiki/Read-copy-update
- Separates update from reclamation
- Allowing both readers and writers to avoid locks altogether
- Writer does not modify the data in place
- Instead, allocate a new element with updated data
- Once updated, the new element replaces the old element using atomic pointer update
- Reader is still referencing the old elemnt and will make the element stay in memory
- This old element must be traced
- Reader should notify the kernel that the reading is completed, so, old element can be reclaimed
- Reader
/**
* rcu_read_lock - mark the beginning of an RCU read-side critical section.
*
* When synchronize_rcu() is invoked on one CPU while other CPUs
* are within RCU read-side critical sections, then the
* synchronize_rcu() is guaranteed to block until after all the other
* CPUs exit their critical sections. Similarly, if call_rcu() is invoked
* on one CPU while other CPUs are within RCU read-side critical
* sections, invocation of the corresponding RCU callback is deferred
* until after the all the other CPUs exit their critical sections.
*
* Note, however, that RCU callbacks are permitted to run concurrently
* with RCU read-side critical sections. One way that this can happen
* is via the following sequence of events: (1) CPU 0 enters an RCU
* read-side critical section, (2) CPU 1 invokes call_rcu() to register
* an RCU callback, (3) CPU 0 exits the RCU read-side critical section,
* (4) CPU 2 enters a RCU read-side critical section, (5) the RCU
* callback is invoked. This is legal, because the RCU read-side critical
* section that was running concurrently with the call_rcu() (and which
* therefore might be referencing something that the corresponding RCU
* callback would free up) has completed before the corresponding
* RCU callback is invoked.
*
* RCU read-side critical sections may be nested. Any deferred actions
* will be deferred until the outermost RCU read-side critical section
* completes.
*
* It is illegal to block while in an RCU read-side critical section.
*/
static inline void rcu_read_lock(void);
/*
* So where is rcu_write_lock()? It does not exist, as there is no
* way for writers to lock out RCU readers. This is a feature, not
* a bug -- this property is what provides RCU's performance benefits.
* Of course, writers must coordinate with each other. The normal
* spinlock primitives work well for this, but any other technique may be
* used as well. RCU does not care how the writers keep out of each
* others' way, as long as they do so.
*/
/**
* rcu_read_unlock - marks the end of an RCU read-side critical section.
*
* See rcu_read_lock() for more information.
*/
static inline void rcu_read_unlock(void);
/**
* rcu_dereference - fetch an RCU-protected pointer in an
* RCU read-side critical section. This pointer may later
* be safely dereferenced.
*
* Inserts memory barriers on architectures that require them
* (currently only the Alpha), and, more importantly, documents
* exactly which pointers are protected by RCU.
*/
#define rcu_dereference(p) ({ \
typeof(p) _________p1 = ACCESS_ONCE(p); \
smp_read_barrier_depends(); \
(_________p1); \
})
- Writer
- Writers update (publish) new data by updating the relevant pointers with rcu_assign_pointer(…), which inserts appropriate barriers to prevent reordering of the initialization and publication, and also serves to document the process.
- call_rcu() is used to submit a call back function to reclaim old data
/**
* rcu_assign_pointer - assign (publicize) a pointer to a newly
* initialized structure that will be dereferenced by RCU read-side
* critical sections. Returns the value assigned.
*
* Inserts memory barriers on architectures that require them
* (pretty much all of them other than x86), and also prevents
* the compiler from reordering the code that initializes the
* structure after the pointer assignment. More importantly, this
* call documents which pointers will be dereferenced by RCU read-side
* code.
*/
#define rcu_assign_pointer(p, v) \
({ \
if (!__builtin_constant_p(v) || \
((v) != NULL)) \
smp_wmb(); \
(p) = (v); \
})
/**
* call_rcu - Queue an RCU callback for invocation after a grace period.
* @head: structure to be used for queueing the RCU updates.
* @func: actual update function to be invoked after the grace period
*
* The update function will be invoked some time after a full grace
* period elapses, in other words after all currently executing RCU
* read-side critical sections have completed. RCU read-side critical
* sections are delimited by rcu_read_lock() and rcu_read_unlock(),
* and may be nested.
*/
extern void call_rcu(struct rcu_head *head,
void (*func)(struct rcu_head *head));
- Reclamation
- After a sufficient grace period, the reclamation infrastructure will call synchronize_rcu() to insure that all reader critical sections have completed, then execute the registered callback functions to reclaim stale structures.
/**
* synchronize_rcu - wait until a grace period has elapsed.
*
* Control will return to the caller some time after a full grace
* period has elapsed, in other words after all currently executing RCU
* read-side critical sections have completed. RCU read-side critical
* sections are delimited by rcu_read_lock() and rcu_read_unlock(),
* and may be nested.
*/
void synchronize_rcu(void);
- Who is handling this callbacks? - RCU_SOFTIRQ
0 include/linux/interrupt.h <global> 390 RCU_SOFTIRQ,
1 kernel/rcutree.c rcu_do_batch 1082 raise_softirq(RCU_SOFTIRQ);
2 kernel/rcutree.c rcu_check_callbacks 1129 raise_softirq(RCU_SOFTIRQ);
3 kernel/rcutree.c __rcu_init 1795 open_softirq(RCU_SOFTIRQ,
rcu_process_callbacks);
static void rcu_process_callbacks(struct softirq_action *unused)
{
/*
* Memory references from any prior RCU read-side critical sections
* executed by the interrupted code must be seen before any RCU
* grace-period manipulations below.
*/
smp_mb(); /* See above block comment. */
__rcu_process_callbacks(&rcu_sched_state,
&__get_cpu_var(rcu_sched_data));
__rcu_process_callbacks(&rcu_bh_state, &__get_cpu_var(rcu_bh_data));
rcu_preempt_process_callbacks();
/*
* Memory references from any later RCU read-side critical sections
* executed by the interrupted code must be seen after any RCU
* grace-period manipulations above.
*/
smp_mb(); /* See above block comment. */
}
/*
* This does the RCU processing work from softirq context for the
* specified rcu_state and rcu_data structures. This may be called
* only from the CPU to whom the rdp belongs.
*/
static void
__rcu_process_callbacks(struct rcu_state *rsp, struct rcu_data *rdp)
{
unsigned long flags;
WARN_ON_ONCE(rdp->beenonline == 0);
/*
* If an RCU GP has gone long enough, go check for dyntick
* idle CPUs and, if needed, send resched IPIs.
*/
if ((long)(ACCESS_ONCE(rsp->jiffies_force_qs) - jiffies) < 0)
force_quiescent_state(rsp, 1);
/*
* Advance callbacks in response to end of earlier grace
* period that some other CPU ended.
*/
rcu_process_gp_end(rsp, rdp);
/* Update RCU state based on any recent quiescent states. */
rcu_check_quiescent_state(rsp, rdp);
/* Does this CPU require a not-yet-started grace period? */
if (cpu_needs_another_gp(rsp, rdp)) {
spin_lock_irqsave(&rcu_get_root(rsp)->lock, flags);
rcu_start_gp(rsp, flags); /* releases above lock */
}
/* If there are callbacks ready, invoke them. */
rcu_do_batch(rsp, rdp);
}
/*
* Invoke any RCU callbacks that have made it to the end of their grace
* period. Thottle as specified by rdp->blimit.
*/
static void rcu_do_batch(struct rcu_state *rsp, struct rcu_data *rdp)
{
unsigned long flags;
struct rcu_head *next, *list, **tail;
int count;
/* If no callbacks are ready, just return.*/
if (!cpu_has_callbacks_ready_to_invoke(rdp))
return;
/*
* Extract the list of ready callbacks, disabling to prevent
* races with call_rcu() from interrupt handlers.
*/
local_irq_save(flags);
list = rdp->nxtlist;
rdp->nxtlist = *rdp->nxttail[RCU_DONE_TAIL];
*rdp->nxttail[RCU_DONE_TAIL] = NULL;
rdp->nxtlist = *rdp->nxttail[RCU_DONE_TAIL];
*rdp->nxttail[RCU_DONE_TAIL] = NULL;
tail = rdp->nxttail[RCU_DONE_TAIL];
for (count = RCU_NEXT_SIZE - 1; count >= 0; count--)
if (rdp->nxttail[count] == rdp->nxttail[RCU_DONE_TAIL])
rdp->nxttail[count] = &rdp->nxtlist;
local_irq_restore(flags);
/* Invoke callbacks. */
count = 0;
while (list) {
next = list->next;
prefetch(next);
__rcu_reclaim(list);
list = next;
if (++count >= rdp->blimit)
break;
}
local_irq_save(flags);
/* Update count, and requeue any remaining callbacks. */
rdp->qlen -= count;
/* Update count, and requeue any remaining callbacks. */
rdp->qlen -= count;
if (list != NULL) {
*tail = rdp->nxtlist;
rdp->nxtlist = list;
for (count = 0; count < RCU_NEXT_SIZE; count++)
if (&rdp->nxtlist == rdp->nxttail[count])
rdp->nxttail[count] = tail;
else
break;
}
/* Reinstate batch limit if we have worked down the excess. */
if (rdp->blimit == LONG_MAX && rdp->qlen <= qlowmark)
rdp->blimit = blimit;
/* Reset ->qlen_last_fqs_check trigger if enough CBs have drained. */
if (rdp->qlen == 0 && rdp->qlen_last_fqs_check != 0) {
rdp->qlen_last_fqs_check = 0;
rdp->n_force_qs_snap = rsp->n_force_qs;
} else if (rdp->qlen < rdp->qlen_last_fqs_check - qhimark)
rdp->qlen_last_fqs_check = rdp->qlen;
rdp->qlen_last_fqs_check = rdp->qlen;
local_irq_restore(flags);
/* Re-raise the RCU softirq if there are callbacks remaining. */
if (cpu_has_callbacks_ready_to_invoke(rdp))
raise_softirq(RCU_SOFTIRQ);
}