Process management
Process
- Process is a program running on CPU
- Kernel handles/calls it task and manages it by allocating task_struct process descriptor
- Maximum tasks system can allocate will be decided by calculating max_threads
- Prior to 2.4 kernels used NR_TASKS which has the fixed number the system can allocate, but, since 2.4, the maximum is based on the physical memory amount by default and also can be changed via sysctl
void __init fork_init(unsigned long mempages)
{
...
/*
* The default maximum number of threads is set to a safe
* value: the thread structures can take up at most half
* of memory.
*/
max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE);
/*
* we need to allow at least 20 threads to boot a system
*/
if(max_threads < 20)
max_threads = 20;
...
}
- mempages represents number of pages available in the system.
- If the system has 512MB of physical memory, mempages will be 131,072.
- If it’s on x86_64 system, max_threads will be ‘4096’
#define THREAD_ORDER 2
#define THREAD_SIZE (PAGE_SIZE << THREAD_ORDER)
PAGE_SIZE=4096
THREAD_SIZE=16384
max_threads = mempages / (8 * 4)
- This value can be changed via kernel.threads-max sysctl parameter. This is defined in the below and modifies max_threads.
{
.ctl_name = KERN_MAX_THREADS,
.procname = "threads-max",
.data = &max_threads, <----- updated in this variable directly
.maxlen = sizeof(int),
.mode = 0644,
.proc_handler = &proc_dointvec,
},
task_struct
- It contains all the information needed to manage a task
- One of the biggest structure in kernel
crash> struct task_struct | grep SIZE
SIZE: 2656
- It’s defined in <linux/sched.h>
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
...
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
struct memcg_oom_info {
struct mem_cgroup *memcg;
gfp_t gfp_mask;
unsigned int may_oom:1;
} memcg_oom;
#endif
#endif /* __GENKYSMS__ */
};
- Each task has it’s own stack in kernel side in addition to a stack in user space
- Kernel side stack is managed using thread_union union structure which is saved in task_struct.stack
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
crash> task_struct.stack ffff883033acd500
stack = 0xffff883032f12000
crash> thread_union 0xffff883032f12000 -o
union thread_union {
[ffff883032f12000] struct thread_info thread_info;
[ffff883032f12000] unsigned long stack[1024];
}
SIZE: 8192
- This thread_union has two purpose - thread_info and stack itself
- thread_info is allocated at the bottom of the stack and contains some task related information
crash> thread_info
struct thread_info {
struct task_struct *task;
struct exec_domain *exec_domain;
__u32 flags;
__u32 status;
__u32 cpu;
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
}
SIZE: 104
crash> thread_info.task 0xffff883032f12000
task = 0xffff883033acd500
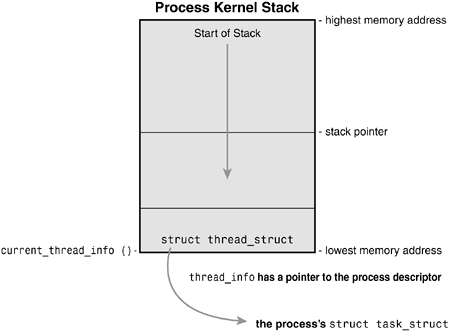
- You can use this stack address in ‘bt -S’ command to check if the calltrace without ‘-S’ is same as ‘bt -S’.
crash> bt
PID: 3117 TASK: ffff883033acd500 CPU: 20 COMMAND: "biz_processor"
#0 [ffff880028343ae0] machine_kexec at ffffffff8103b68b
#1 [ffff880028343b40] crash_kexec at ffffffff810c9852
#2 [ffff880028343c10] oops_end at ffffffff8152e070
#3 [ffff880028343c40] no_context at ffffffff8104c80b
#4 [ffff880028343c90] __bad_area_nosemaphore at ffffffff8104ca95
#5 [ffff880028343ce0] bad_area_nosemaphore at ffffffff8104cb63
#6 [ffff880028343cf0] __do_page_fault at ffffffff8104d2bf
#7 [ffff880028343e10] do_page_fault at ffffffff8152ffbe
#8 [ffff880028343e40] page_fault at ffffffff8152d375
[exception RIP: setup_intel_arch_watchdog+214]
RIP: ffffffff810310f6 RSP: ffff880028343ef0 RFLAGS: 00010086
RAX: 00000000fffffffb RBX: 0000000000000067 RCX: 0000000000000067
RDX: 0000000000000000 RSI: 00000000fffffffd RDI: 0000000000000067
RBP: ffff880028343f18 R8: 0000000032b0f32c R9: 00007fffd86e5c40
R10: 0000000000000029 R11: a3d70a3d70a3d70b R12: ffff880832b0f32c
R13: 0000000000000067 R14: ffff883032f13f58 R15: 00007fffd86e5d70
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0000
#9 [ffff880028343f60] handle_irq at ffffffff8100fc99
#10 [ffff880028343f80] do_IRQ at ffffffff81533b3c
--- <IRQ stack> ---
#11 [ffff883032f13f58] ret_from_intr at ffffffff8100b9d3
RIP: 0000003e76e9da95 RSP: 00007fffd86e5c40 RFLAGS: 00000202
RAX: 000000000f4dd498 RBX: 00007fffd86e5c90 RCX: 0000003e7358fe90
RDX: 0000000000000000 RSI: 000000001a033628 RDI: 00007fffd86e5d00
RBP: ffffffff8100b9ce R8: 00000000ffffffff R9: 0000000000000000
R10: 0000000000000029 R11: a3d70a3d70a3d70b R12: 0000000011242460
R13: 0000000000000040 R14: 0000000000000012 R15: 0000000000000000
ORIG_RAX: ffffffffffffff58 CS: 0033 SS: 002b
crash> bt -S 0xffff883033acd500
PID: 3117 TASK: ffff883033acd500 CPU: 20 COMMAND: "biz_processor"
#0 [ffff880028343ae0] machine_kexec+395 at ffffffff8103b68b
#1 [ffff880028343b40] crash_kexec+114 at ffffffff810c9852
#2 [ffff880028343c10] oops_end+192 at ffffffff8152e070
#3 [ffff880028343c40] no_context+251 at ffffffff8104c80b
#4 [ffff880028343c90] __bad_area_nosemaphore+293 at ffffffff8104ca95
#5 [ffff880028343ce0] bad_area_nosemaphore+19 at ffffffff8104cb63
#6 [ffff880028343cf0] __do_page_fault+799 at ffffffff8104d2bf
#7 [ffff880028343e10] do_page_fault+62 at ffffffff8152ffbe
#8 [ffff880028343e40] page_fault+37 at ffffffff8152d375
[exception RIP: setup_intel_arch_watchdog+214]
RIP: ffffffff810310f6 RSP: ffff880028343ef0 RFLAGS: 00010086
RAX: 00000000fffffffb RBX: 0000000000000067 RCX: 0000000000000067
RDX: 0000000000000000 RSI: 00000000fffffffd RDI: 0000000000000067
RBP: ffff880028343f18 R8: 0000000032b0f32c R9: 00007fffd86e5c40
R10: 0000000000000029 R11: a3d70a3d70a3d70b R12: ffff880832b0f32c
R13: 0000000000000067 R14: ffff883032f13f58 R15: 00007fffd86e5d70
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0000
#9 [ffff880028343f60] handle_irq+73 at ffffffff8100fc99
#10 [ffff880028343f80] do_IRQ+108 at ffffffff81533b3c
--- <IRQ stack> ---
#11 [ffff883032f13f58] ret_from_intr at ffffffff8100b9d3
RIP: 0000003e76e9da95 RSP: 00007fffd86e5c40 RFLAGS: 00000202
RAX: 000000000f4dd498 RBX: 00007fffd86e5c90 RCX: 0000003e7358fe90
RDX: 0000000000000000 RSI: 000000001a033628 RDI: 00007fffd86e5d00
RBP: ffffffff8100b9ce R8: 00000000ffffffff R9: 0000000000000000
R10: 0000000000000029 R11: a3d70a3d70a3d70b R12: 0000000011242460
R13: 0000000000000040 R14: 0000000000000012 R15: 0000000000000000
ORIG_RAX: ffffffffffffff58 CS: 0033 SS: 002b
Process status
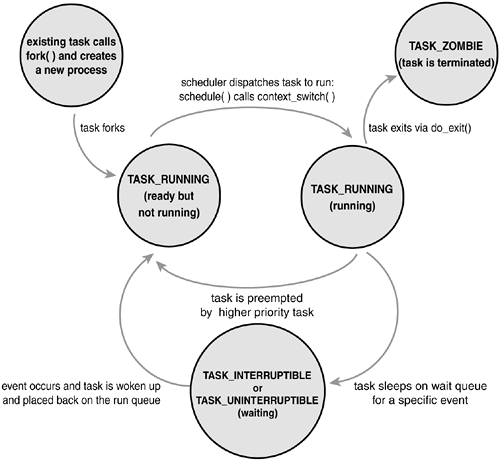
- A process can be in one of the below state which can be checked from task_struct.state
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_DEAD 64
crash> task_struct.state ffff88283384b540
state = 1
crash> ps ffff88283384b540
PID PPID CPU TASK ST %MEM VSZ RSS COMM
35929 1 20 ffff88283384b540 IN 0.0 52580 328 vsftpd
crash> task_struct.state ffff880833a16ae0
state = 64
crash> ps ffff880833a16ae0
PID PPID CPU TASK ST %MEM VSZ RSS COMM
29518 29517 13 ffff880833a16ae0 ZO 0.0 0 0 sh
crash> task_struct.state ffff882032e96aa0
state = 0
crash> ps ffff882032e96aa0
PID PPID CPU TASK ST %MEM VSZ RSS COMM
> 29531 1 36 ffff882032e96aa0 RU 0.0 487440 3264 eocgsubagent
- Each state has the meaning of
- TASK_RUNNING : It’s running on a CPU or awaiting for a chance
- TASK_INTERRUPTIBLE : It’s in sleep and can be awake by wakup() call or by a signal generated by kill command
- TASK_UNINTERRUPTIBLE: It’s in sleep and only can be awake by wakeup() call. Even kill -9 can’t awake nor kill this process
- TASK_DEAD : Task’s already cleared most resources and only exist to give its parent a chance to get exit code. It’ll be removed from memory once parent calls wait4() or waitpid() system calls
Process creation
- Process can be created by one of the below three system calls
#include <unistd.h>
pid_t fork(void);
fork() creates a new process by duplicating the calling process.
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
vfork() is a special case of clone(2). It is used to create new processes without copying the page tables of the parent process.
#define _GNU_SOURCE
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
Unlike fork(2), these calls allow the child process to share parts of
its execution context with the calling process, such as the memory
space, the table of file descriptors, and the table of signal handlers.
- These calls are all coming to the same kernel function - sys_fork() which calls do_fork()
int sys_fork(struct pt_regs *regs)
{
return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL);
}
- do_fork()’s main job has three parts
- copying task_struct from it’s parent
- wake up the child process
- await until child process terminated if CLONE_VFORK is specified
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Do some preliminary argument and permissions checking before we
* actually start allocating stuff
*/
if (clone_flags & (CLONE_NEWUSER | CLONE_NEWPID)) {
if (clone_flags & (CLONE_THREAD|CLONE_PARENT))
return -EINVAL;
}
if (clone_flags & CLONE_NEWUSER) {
/* hopefully this check will go away when userns support is
* complete
*/
if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) ||
!capable(CAP_SETGID))
return -EPERM;
}
/*
* We hope to recycle these flags after 2.6.26
*/
if (unlikely(clone_flags & CLONE_STOPPED)) {
static int __read_mostly count = 100;
if (count > 0 && printk_ratelimit()) {
char comm[TASK_COMM_LEN];
count--;
printk(KERN_INFO "fork(): process `%s' used deprecated "
"clone flags 0x%lx\n",
get_task_comm(comm, current),
clone_flags & CLONE_STOPPED);
}
}
/*
* When called from kernel_thread, don't do user tracing stuff.
*/
if (likely(user_mode(regs)))
trace = tracehook_prepare_clone(clone_flags);
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
trace_sched_process_fork(current, p);
nr = task_pid_vnr(p);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
audit_finish_fork(p);
tracehook_report_clone(regs, clone_flags, nr, p);
/*
* We set PF_STARTING at creation in case tracing wants to
* use this to distinguish a fully live task from one that
* hasn't gotten to tracehook_report_clone() yet. Now we
* clear it and set the child going.
*/
p->flags &= ~PF_STARTING;
if (unlikely(clone_flags & CLONE_STOPPED)) {
/*
* We'll start up with an immediate SIGSTOP.
*/
sigaddset(&p->pending.signal, SIGSTOP);
set_tsk_thread_flag(p, TIF_SIGPENDING);
__set_task_state(p, TASK_STOPPED);
} else {
wake_up_new_task(p, clone_flags);
}
tracehook_report_clone_complete(trace, regs,
clone_flags, nr, p);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
tracehook_report_vfork_done(p, nr);
}
} else {
nr = PTR_ERR(p);
}
return nr;
}
- Launching a new program involves two steps
- fork() to create a new process space (copying a task_struct)
- execve() to load a new binary into this new task_struct
Kernel thread creation
- Kernel also can create a process with kernel context
- The kernel delegates some critical tasks to intermittently running kernel threads eg. flushing disk caches, servicing softirqs, flushing dirty buffers to disk
- Simpler version
int kernel_thread(int (*fn)(void *), void *arg, unsigned long flags);
** examples **
static noinline void __init_refok rest_init(void)
__releases(kernel_lock)
{
...
kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
...
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
...
}
- Enhanced version of kernel thread creation methods
/**
* kthread_create - create a kthread.
* @threadfn: the function to run until signal_pending(current).
* @data: data ptr for @threadfn.
* @namefmt: printf-style name for the thread.
*
* Description: This helper function creates and names a kernel
* thread. The thread will be stopped: use wake_up_process() to start
* it. See also kthread_run(), kthread_create_on_cpu().
*
* When woken, the thread will run @threadfn() with @data as its
* argument. @threadfn() can either call do_exit() directly if it is a
* standalone thread for which noone will call kthread_stop(), or
* return when 'kthread_should_stop()' is true (which means
* kthread_stop() has been called). The return value should be zero
* or a negative error number; it will be passed to kthread_stop().
*
* Returns a task_struct or ERR_PTR(-ENOMEM).
*/
struct task_struct *kthread_create(int (*threadfn)(void *data),
void *data,
const char namefmt[],
...);
/**
* kthread_stop - stop a thread created by kthread_create().
* @k: thread created by kthread_create().
*
* Sets kthread_should_stop() for @k to return true, wakes it, and
* waits for it to exit. This can also be called after kthread_create()
* instead of calling wake_up_process(): the thread will exit without
* calling threadfn().
*
* If threadfn() may call do_exit() itself, the caller must ensure
* task_struct can't go away.
*
* Returns the result of threadfn(), or %-EINTR if wake_up_process()
* was never called.
*/
int kthread_stop(struct task_struct *k);
/**
* kthread_should_stop - should this kthread return now?
*
* When someone calls kthread_stop() on your kthread, it will be woken
* and this will return true. You should then return, and your return
* value will be passed through to kthread_stop().
*/
int kthread_should_stop(void);
/**
* kthread_bind - bind a just-created kthread to a cpu.
* @p: thread created by kthread_create().
* @cpu: cpu (might not be online, must be possible) for @k to run on.
*
* Description: This function is equivalent to set_cpus_allowed(),
* except that @cpu doesn't need to be online, and the thread must be
* stopped (i.e., just returned from kthread_create()).
*
* Function lives here instead of kthread.c because it messes with
* scheduler internals which require locking.
*/
void kthread_bind(struct task_struct *p, unsigned int cpu);
/**
* wake_up_process - Wake up a specific process
* @p: The process to be woken up.
*
* Attempt to wake up the nominated process and move it to the set of runnable
* processes. Returns 1 if the process was woken up, 0 if it was already
* running.
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
int wake_up_process(struct task_struct *p);
- Example : watchdog/X
static int watchdog_enable(int cpu)
{
struct task_struct *p = per_cpu(softlockup_watchdog, cpu);
int err = 0;
/* enable the perf event */
err = watchdog_nmi_enable(cpu);
/* Regardless of err above, fall through and start softlockup */
/* create the watchdog thread */
if (!p) {
p = kthread_create(watchdog, (void *)(unsigned long)cpu, "watchdog/%d", cpu); <--- Step 1
if (IS_ERR(p)) {
printk(KERN_ERR "softlockup watchdog for %i failed\n", cpu);
if (!err)
/* if hardlockup hasn't already set this */
err = PTR_ERR(p);
goto out;
}
kthread_bind(p, cpu); <--- Step 2 (Optional)
per_cpu(watchdog_touch_ts, cpu) = 0;
per_cpu(softlockup_watchdog, cpu) = p;
wake_up_process(p); <--- Step 3
}
out:
return err;
}
/*
* The watchdog thread - touches the timestamp.
*/
static int watchdog(void *unused)
{
struct sched_param param = { .sched_priority = MAX_RT_PRIO-1 };
struct hrtimer *hrtimer = &__raw_get_cpu_var(watchdog_hrtimer);
sched_setscheduler(current, SCHED_FIFO, ¶m);
/* initialize timestamp */
__touch_watchdog();
/* kick off the timer for the hardlockup detector */
/* done here because hrtimer_start can only pin to smp_processor_id() */
hrtimer_start(hrtimer, ns_to_ktime(get_sample_period()),
HRTIMER_MODE_REL_PINNED);
set_current_state(TASK_INTERRUPTIBLE);
/*
* Run briefly once per second to reset the softlockup timestamp.
* If this gets delayed for more than 60 seconds then the
* debug-printout triggers in watchdog_timer_fn().
*/
while (!kthread_should_stop()) {
__touch_watchdog();
schedule();
if (kthread_should_stop())
break;
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
}
- What’s the main difference between kernel thread and user processes
- Kernel thread runs in higher priviledge and has the full access to the system
- Kernel threads don’t have ‘mm_struct’ which restricts the operations related to coping data between kernel and user spaces.
* Normal process
crash> task_struct.comm,mm ffff881fc4adc500
comm = "sshd\000)\000\000\060\000\000\000\000\000\000"
mm = 0xffff883fce91a580
* Kernel thread
crash: command not found: mm
crash> task_struct.comm,mm ffff881fd1862280
comm = "watchdog/46\000\000\000\000"
mm = 0x0
Process termination
- Process termination is happening by calling ‘sys_exit()’ which is calling ‘do_exit()’
- Release the resources allocated for the process
- Set the exit code into task_struct->exit_code
- Complete vfork if it has CLONE_VFORK in mm_release() called from mm_exit()
- Set the state to TASK_DEAD
- Goes into sleep and never wakes up
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code&0xff)<<8);
}
NORET_TYPE void do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
profile_task_exit(tsk);
WARN_ON(atomic_read(&tsk->fs_excl));
if (unlikely(in_interrupt()))
panic("Aiee, killing interrupt handler!");
if (unlikely(!tsk->pid))
panic("Attempted to kill the idle task!");
/*
* If do_exit is called because this processes oopsed, it's possible
* that get_fs() was left as KERNEL_DS, so reset it to USER_DS before
* continuing. Amongst other possible reasons, this is to prevent
* mm_release()->clear_child_tid() from writing to a user-controlled
* kernel address.
*/
set_fs(USER_DS);
tracehook_report_exit(&code);
validate_creds_for_do_exit(tsk);
/*
* We're taking recursive faults here in do_exit. Safest is to just
* leave this task alone and wait for reboot.
*/
if (unlikely(tsk->flags & PF_EXITING)) {
printk(KERN_ALERT
"Fixing recursive fault but reboot is needed!\n");
/*
* We can do this unlocked here. The futex code uses
* this flag just to verify whether the pi state
* cleanup has been done or not. In the worst case it
* loops once more. We pretend that the cleanup was
* done as there is no way to return. Either the
* OWNER_DIED bit is set by now or we push the blocked
* task into the wait for ever nirwana as well.
*/
tsk->flags |= PF_EXITPIDONE;
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
exit_irq_thread();
exit_signals(tsk); /* sets PF_EXITING */
/*
* tsk->flags are checked in the futex code to protect against
* an exiting task cleaning up the robust pi futexes.
*/
smp_mb();
spin_unlock_wait(&tsk->pi_lock);
if (unlikely(in_atomic()))
printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n",
current->comm, task_pid_nr(current),
preempt_count());
acct_update_integrals(tsk);
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) {
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm);
}
acct_collect(code, group_dead);
if (group_dead)
tty_audit_exit();
if (unlikely(tsk->audit_context))
audit_free(tsk);
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
exit_mm(tsk);
if (group_dead)
acct_process();
trace_sched_process_exit(tsk);
exit_sem(tsk);
exit_shm(tsk);
exit_files(tsk);
exit_fs(tsk);
check_stack_usage();
exit_thread();
cgroup_exit(tsk, 1);
if (group_dead && tsk->signal->leader)
disassociate_ctty(1);
module_put(task_thread_info(tsk)->exec_domain->module);
proc_exit_connector(tsk);
/*
* Flush inherited counters to the parent - before the parent
* gets woken up by child-exit notifications.
*/
perf_event_exit_task(tsk);
exit_notify(tsk, group_dead);
#ifdef CONFIG_NUMA
task_lock(tsk);
mpol_put(tsk->mempolicy);
tsk->mempolicy = NULL;
task_unlock(tsk);
#endif
#ifdef CONFIG_FUTEX
if (unlikely(current->pi_state_cache))
kfree(current->pi_state_cache);
#endif
/*
* Make sure we are holding no locks:
*/
debug_check_no_locks_held(tsk);
/*
* We can do this unlocked here. The futex code uses this flag
* just to verify whether the pi state cleanup has been done
* or not. In the worst case it loops once more.
*/
tsk->flags |= PF_EXITPIDONE;
if (tsk->io_context)
exit_io_context(tsk);
if (tsk->splice_pipe)
__free_pipe_info(tsk->splice_pipe);
validate_creds_for_do_exit(tsk);
preempt_disable();
exit_rcu();
wait_for_rqlock();
/* causes final put_task_struct in finish_task_switch(). */
tsk->state = TASK_DEAD;
schedule();
BUG();
/* Avoid "noreturn function does return". */
for (;;)
cpu_relax(); /* For when BUG is null */
}
- How to check return code and signal from a zombie process
Normal exit
crash> ps | grep a.out
75442 68908 0 ffff880136a1a280 IN 0.0 4160 412 a.out
75443 75442 1 ffff880136a1c500 ZO 0.0 0 0 a.out
crash> task_struct.exit_code,signal ffff880136a1c500
exit_code = 1792
signal = 0xffff880135e71f80
crash> pd 1792/256
$3 = 7
crash> signal_struct.group_exit_code 0xffff880135e71f80
group_exit_code = 0
Terminated by a signal
crash> ps | grep a.out
75564 68908 1 ffff8800bba3d080 IN 0.0 4160 412 a.out
75565 75564 0 ffff8800bba39700 ZO 0.0 0 0 a.out
crash> task_struct.exit_code,signal ffff8800bba39700
exit_code = 15
signal = 0xffff88009f898900
crash> signal_struct.group_exit_code 0xffff88009f898900
group_exit_code = 15
In case of segmentation fault
crash> ps | grep a.out
75586 68908 0 ffff880132bf6780 IN 0.0 4160 408 a.out
75587 75586 0 ffff880132bf5080 ZO 0.0 0 0 a.out
crash> task_struct.exit_code,signal ffff880132bf5080
exit_code = 139
signal = 0xffff880135e75a00
crash> signal_struct.group_exit_code 0xffff880135e75a00
group_exit_code = 139
crash> pd 139%64
$7 = 11
Process Scheduling
schedule()
- It’s switching contexts among processes
- Pick a next task to run
- Stop the current process and save all the register values into task_struct.thread (switch_to())
crash> task_struct.thread
struct task_struct {
[1688] struct thread_struct thread;
}
crash> thread_struct
struct thread_struct {
struct desc_struct tls_array[3];
unsigned long sp0;
unsigned long sp;
unsigned long usersp;
unsigned short es;
unsigned short ds;
unsigned short fskernel/internals/index;
unsigned short gskernel/internals/index;
unsigned long fs;
unsigned long gs;
struct perf_event *ptrace_bps[4];
unsigned long debugreg6;
unsigned long ptrace_dr7;
unsigned long cr2;
unsigned long trap_nr;
unsigned long error_code;
struct fpu fpu;
unsigned long *io_bitmap_ptr;
unsigned long iopl;
unsigned int io_bitmap_max;
}
SIZE: 184
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)
scheduling classes
- 2.6 kernel has multiple scheduling classes and a process belongs to one of them
- scheduling class is defined in ‘sched_class’
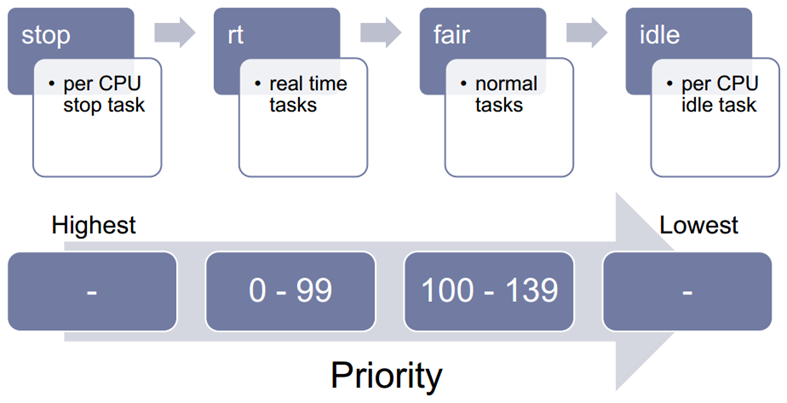
- Setting scheduler for a process is happening in ‘sched_setscheduler()’.
int sched_setscheduler(struct task_struct *p, int policy,
struct sched_param *param)
{
return __sched_setscheduler(p, policy, param, true);
}
static int __sched_setscheduler(struct task_struct *p, int policy,
struct sched_param *param, bool user)
{
int retval, oldprio, oldpolicy = -1, on_rq, running;
unsigned long flags;
const struct sched_class *prev_class;
struct rq *rq;
int reset_on_fork;
/* may grab non-irq protected spin_locks */
BUG_ON(in_interrupt());
recheck:
/* double check policy once rq lock held */
if (policy < 0) {
reset_on_fork = p->sched_reset_on_fork;
policy = oldpolicy = p->policy;
} else {
reset_on_fork = !!(policy & SCHED_RESET_ON_FORK);
policy &= ~SCHED_RESET_ON_FORK;
if (policy != SCHED_FIFO && policy != SCHED_RR &&
policy != SCHED_NORMAL && policy != SCHED_BATCH &&
policy != SCHED_IDLE)
return -EINVAL;
}
...
oldprio = p->prio;
prev_class = p->sched_class;
__setscheduler(rq, p, policy, param->sched_priority);
...
}
__setscheduler(struct rq *rq, struct task_struct *p, int policy, int prio)
{
BUG_ON(p->se.on_rq);
p->policy = policy;
switch (p->policy) {
case SCHED_NORMAL:
case SCHED_BATCH:
case SCHED_IDLE:
p->sched_class = &fair_sched_class;
break;
case SCHED_FIFO:
case SCHED_RR:
p->sched_class = &rt_sched_class;
break;
}
p->rt_priority = prio;
p->normal_prio = normal_prio(p);
/* we are holding p->pi_lock already */
p->prio = rt_mutex_getprio(p);
set_load_weight(p);
}
- task_struct.policy can have one of the below values
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2 #define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
-
SCHED_FIFO and SCHED_RR are so called “real-time” policies. They implement the fixed-priority real-time scheduling specified by the POSIX standard. Tasks with these policies preempt every other task, which can thus easily go into starvation (if they don’t release the CPU).
-
The difference between SCHED_FIFO and SCHED_RR is that among tasks with the same priority, SCHED_RR performs a round-robin with a certain timeslice; SCHED_FIFO, instead, needs the task to explicitly yield the processor.
-
SCHED_OTHER is the common round-robin time-sharing scheduling policy that schedules a task for a certain timeslice depending on the other tasks running in the system.
-
Examples
crash> task_struct.comm,policy,sched_class ffff8810190fa080
comm = "swapper\000\000\000\000\000\000\000\000"
policy = 0
sched_class = 0xffffffff8160dd20 <idle_sched_class>
crash> task_struct.comm,policy,sched_class ffff882015cff500
comm = "bash\000\000\000\000\000\000\000\000\000\000\000"
policy = 0
sched_class = 0xffffffff8160dc40 <fair_sched_class>
crash> task_struct.comm,policy,sched_class ffff881019968040
comm = "migration/0\000\000\000\000"
policy = 1
sched_class = 0xffffffff8160dee0 <rt_sched_class>
RT scheduling
static const struct sched_class rt_sched_class = {
.next = &fair_sched_class,
.enqueue_task = enqueue_task_rt,
.dequeue_task = dequeue_task_rt,
.yield_task = yield_task_rt,
.check_preempt_curr = check_preempt_curr_rt,
.pick_next_task = pick_next_task_rt,
.put_prev_task = put_prev_task_rt,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_rt,
.load_balance = load_balance_rt,
.move_one_task = move_one_task_rt,
.set_cpus_allowed = set_cpus_allowed_rt,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.pre_schedule = pre_schedule_rt,
.post_schedule = post_schedule_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
#endif
.set_curr_task = set_curr_task_rt,
.task_tick = task_tick_rt,
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
};
CFS Scheduling class
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_fair,
.load_balance = load_balance_fair,
.move_one_task = move_one_task_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_waking = task_waking_fair,
#endif
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.moved_group = task_move_group_fair,
#endif
};
Idle scheduling class
static const struct sched_class idle_sched_class = {
/* .next is NULL */
/* no enqueue/yield_task for idle tasks */
/* dequeue is not valid, we print a debug message there: */
.dequeue_task = dequeue_task_idle,
.check_preempt_curr = check_preempt_curr_idle,
.pick_next_task = pick_next_task_idle,
.put_prev_task = put_prev_task_idle,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_idle,
.load_balance = load_balance_idle,
.move_one_task = move_one_task_idle,
#endif
.set_curr_task = set_curr_task_idle,
.task_tick = task_tick_idle,
.get_rr_interval = get_rr_interval_idle,
.prio_changed = prio_changed_idle,
.switched_to = switched_to_idle,
/* no .task_new for idle tasks */
};
- You can find whole scheduling classes by running the below.
crash> sym stop_sched_class
ffffffff8160c020 (r) stop_sched_class
crash> list ffffffff8160c020 -o sched_class.next -s sched_class.enqueue_task,dequeue_task
ffffffff8160c020
enqueue_task = 0xffffffff81053cd0 <enqueue_task_stop>
dequeue_task = 0xffffffff81053ce0 <dequeue_task_stop>
ffffffff8160c100
enqueue_task = 0xffffffff8106a130 <enqueue_task_rt>
dequeue_task = 0xffffffff8106b1d0 <dequeue_task_rt>
ffffffff8160be60
enqueue_task = 0xffffffff81069320 <enqueue_task_fair>
dequeue_task = 0xffffffff81069ba0 <dequeue_task_fair>
ffffffff8160bf40
enqueue_task = 0x0
dequeue_task = 0xffffffff810597e0 <dequeue_task_idle>
Scheduling Step 1 : Preparing the scheduling
- Find runqueue and the current task
asmlinkage void __sched schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable();
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_sched_qs(cpu);
prev = rq->curr;
switch_count = &prev->nivcsw;
release_kernel_lock(prev);
Scheduling Step 2 : Deactivate the current task
- If nothing urgent comes up and this process has pending signal, then it’ll be re-activated
- Otherwise, it’ll be deactivated and removed from the runqueue
need_resched_nonpreemptible:
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
spin_lock_irq(&rq->lock);
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev)))
prev->state = TASK_RUNNING;
else
deactivate_task(rq, prev, DEQUEUE_SLEEP);
switch_count = &prev->nvcsw;
}
- deactivate_task() is removing the task from runqueue
static void deactivate_task(struct rq *rq, struct task_struct *p, int flags)
{
if (task_contributes_to_load(p))
rq->nr_uninterruptible++;
dequeue_task(rq, p, flags);
}
static void dequeue_task(struct rq *rq, struct task_struct *p, int flags)
{
update_rq_clock(rq);
sched_info_dequeued(p);
p->sched_class->dequeue_task(rq, p, flags);
p->se.on_rq = 0;
}
static void dequeue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
int task_sleep = flags & DEQUEUE_SLEEP;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
dequeue_entity(cfs_rq, se, flags);
...
static void __dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (cfs_rq->rb_leftmost == &se->run_node) {
struct rb_node *next_node;
next_node = rb_next(&se->run_node);
cfs_rq->rb_leftmost = next_node;
}
rb_erase(&se->run_node, &cfs_rq->tasks_timeline);
}
Scheduling Step 3 : Find next task to run
- Pick up a next task to run
- The way it checks the next task is all depends on sched_class.
pre_schedule(rq, prev);
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
put_prev_task(rq, prev);
next = pick_next_task(rq);
clear_tsk_need_resched(prev);
rq->skip_clock_update = 0;
- Picking up is happening in ‘pick_next_task()’
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
if (likely(rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
BUG(); /* the idle class will always have a runnable task */
}
static struct task_struct *pick_next_task_fair(struct rq *rq)
{
struct task_struct *p;
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
if (unlikely(!cfs_rq->nr_running))
return NULL;
do {
se = pick_next_entity(cfs_rq);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
hrtick_start_fair(rq, p);
return p;
}
Scheduling Step 4 : Switching tasks
- Low level context switching is happening
- Update scheduling related statistics
if (likely(prev != next)) {
sched_info_switch(prev, next);
perf_event_task_sched_out(prev, next);
rq->nr_switches++;
rq->curr = next;
++*switch_count;
context_switch(rq, prev, next); /* unlocks the rq */
/*
* the context switch might have flipped the stack from under
* us, hence refresh the local variables.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
spin_unlock_irq(&rq->lock);
post_schedule(rq);