#ifdef CONFIG_X86_32
/*
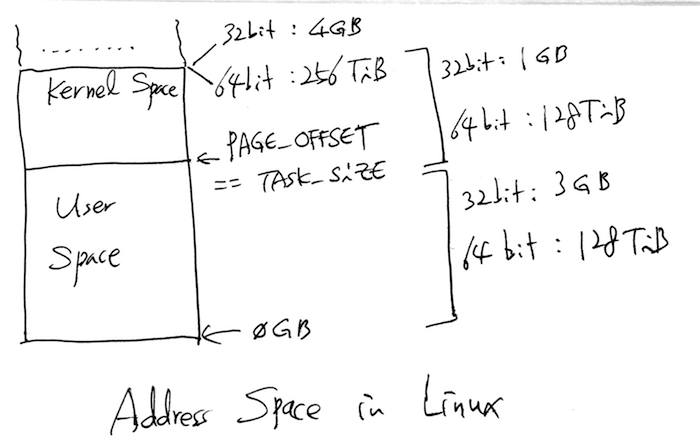
* User space process size: 3GB (default).
*/
#define TASK_SIZE PAGE_OFFSET
#define TASK_SIZE_MAX TASK_SIZE
#else
/*
* User space process size. 47bits minus one guard page.
*/
#define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)
/* This decides where the kernel will search for a free chunk of vm
* space during mmap's.
*/
#define IA32_PAGE_OFFSET ((current->personality & ADDR_LIMIT_3GB) ? \
0xc0000000 : 0xFFFFe000)
#define TASK_SIZE (test_thread_flag(TIF_IA32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
(1UL << 47) == 140737488355328 == 128TiB
(0x800000000000UL - 4096) == 140737488351232 == 0x7ffffffff000
(0xfffffff00000-0x800000000000) == 0x7ffffff00000 == 128 TiB
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
/*
* PMD_SHIFT determines the size of the area a middle-level
* page table can map
*/
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
/*
* entries per page directory level
*/
#define PTRS_PER_PTE 512
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE - 1))
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE - 1))
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE - 1))
/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page.
*/
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
atomic_t _count; /* Usage count, see below. */
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
union {
struct {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUS
spinlock_t ptl;
#endif
};
pgoff_t kernel/internals/index; /* Our offset within mapping. */
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
};
crash> kmem -p | head
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
ffff810100000000 0 0 0 1 400
ffff810100000038 1000 0 0 1 400
ffff810100000070 2000 0 0 1 400
ffff8101000000a8 3000 0 0 1 400
ffff8101000000e0 4000 0 0 1 400
ffff810100000118 5000 0 0 1 400
ffff810100000150 6000 0 0 1 400
ffff810100000188 7000 0 0 1 400
ffff8101000001c0 8000 0 0 1 400
crash> kmem -g 400
FLAGS: 400
PAGE-FLAG BIT VALUE
PG_reserved 10 0000400
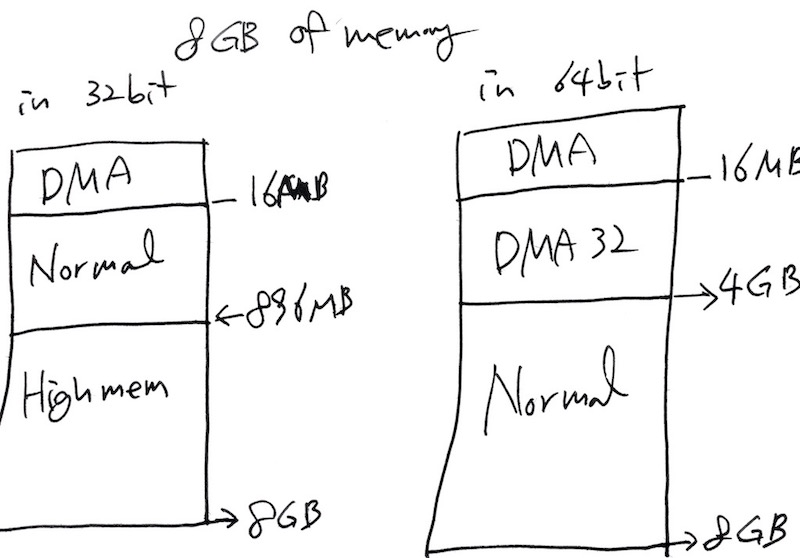
/*
* On machines where it is needed (eg PCs) we divide physical memory
* into multiple physical zones. On a 32bit PC we have 4 zones:
*
* ZONE_DMA < 16 MB ISA DMA capable memory
* ZONE_DMA32 0 MB Empty
* ZONE_NORMAL 16-896 MB direct mapped by the kernel
* ZONE_HIGHMEM > 896 MB only page cache and user processes
*/
struct zone {
/* Fields commonly accessed by the page allocator */
unsigned long free_pages;
unsigned long pages_min, pages_low, pages_high;
/*
* We don't know if the memory that we're going to allocate will be freeable
* or/and it will be released eventually, so to avoid totally wasting several
* GB of ram we must reserve some of the lower zone memory (otherwise we risk
* to run OOM on the lower zones despite there's tons of freeable ram
* on the higher zones). This array is recalculated at runtime if the
* sysctl_lowmem_reserve_ratio sysctl changes.
....
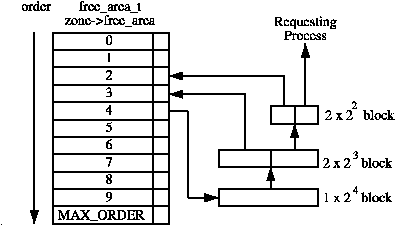
struct free_area free_area[MAX_ORDER];
ZONE_PADDING(_pad1_)
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct list_head active_list;
struct list_head inactive_list;
unsigned long nr_scan_active;
unsigned long nr_scan_inactive;
unsigned long nr_active;
unsigned long nr_inactive;
unsigned long pages_scanned; /* since last reclaim */
int all_unreclaimable; /* All pages pinned */
/* A count of how many reclaimers are scanning this zone */
atomic_t reclaim_in_progress;
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
...
char *name;
} ____cacheline_internodealigned_in_smp;
Node 0, zone DMA 0 0 1 1 1 1 1 1 0 1 3
Node 0, zone DMA32 1 5 26 9 64 72 28 12 7 6 452
Node 0, zone Normal 24 42 32 15 9 73 52 30 15 3 616
crash> kmem -f
NODE
0
ZONE NAME SIZE FREE MEM_MAP START_PADDR START_MAPNR
0 DMA 4096 2667 ffff810100000000 0 0
AREA SIZE FREE_AREA_STRUCT BLOCKS PAGES
0 4k ffff810000053858 3 3
1 8k ffff810000053870 2 4
2 16k ffff810000053888 1 4
3 32k ffff8100000538a0 2 16
4 64k ffff8100000538b8 3 48
5 128k ffff8100000538d0 1 32
6 256k ffff8100000538e8 0 0
7 512k ffff810000053900 0 0
8 1024k ffff810000053918 2 512
9 2048k ffff810000053930 0 0
10 4096k ffff810000053948 2 2048
ZONE NAME SIZE FREE MEM_MAP START_PADDR START_MAPNR
1 DMA32 1044480 402083 ffff810100038000 1000000 4096
AREA SIZE FREE_AREA_STRUCT BLOCKS PAGES
...
ZONE NAME SIZE FREE MEM_MAP START_PADDR START_MAPNR
3 HighMem 0 0 0 0 0
nr_free_pages: 4904196 (verified)
/* Not allowing to allocate for HIGHMEM, otherwise calls alloc_pages() */
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
/* Allocate 2 ^ order's contiguous physical pages */
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order);
/* Allocate 2 ^ 0 page (1 page) */
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0);
$ cat /proc/buddyinfo
Node 0, zone DMA 2 1 1 1 1 0 1 0 1 1 3
Node 0, zone DMA32 19000 1032 173 65 31 6 2 0 0 0 0
Node 0, zone Normal 39681 280 46 18 2 0 0 0 0 0 0
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
...
/* First allocation attempt */
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,
zonelist, high_zoneidx, ALLOC_WMARK_LOW|ALLOC_CPUSET,
preferred_zone, migratetype);
...
return page;
}
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask, unsigned int order,
struct zonelist *zonelist, int high_zoneidx, int alloc_flags,
struct zone *preferred_zone, int migratetype)
{
...
/*
* Scan zonelist, looking for a zone with enough free.
* See also cpuset_zone_allowed() comment in kernel/cpuset.c.
*/
for_each_zone_zonelist_nodemask(zone, z, zonelist,
high_zoneidx, nodemask) {
...
}
...
try_this_zone:
page = buffered_rmqueue(preferred_zone, zone, order,
gfp_mask, migratetype);
if (page)
break;
...
}
static inline
struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, int order, gfp_t gfp_flags,
int migratetype)
{
...
spin_lock_irqsave(&zone->lock, flags);
page = __rmqueue(zone, order, migratetype);
spin_unlock(&zone->lock);
...
}
/*
* Go through the free lists for the given migratetype and remove
* the smallest available page from the freelists
*/
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area * area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,
struct page, lru);
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
return page;
}
return NULL;
}
/* Returns the next zone at or below highest_zoneidx in a zonelist */
struct zoneref *next_zones_zonelist(struct zoneref *z,
enum zone_type highest_zoneidx,
nodemask_t *nodes,
struct zone **zone)
{
/*
* Find the next suitable zone to use for the allocation.
* Only filter based on nodemask if it's set
*/
if (likely(nodes == NULL))
while (zonelist_zone_idx(z) > highest_zoneidx)
z++;
else
while (zonelist_zone_idx(z) > highest_zoneidx ||
(z->zone && !zref_in_nodemask(z, nodes)))
z++;
*zone = zonelist_zone(z);
return z;
}
crash> node_data
node_data = $2 = 0xffffffff81c16ae0 <node_data>
crash> rd 0xffffffff81c16ae0
ffffffff81c16ae0: ffff880000010000 ........
crash> pglist_data.node_zonelists ffff880000010000 | grep -v 'zone = 0x0,' | grep 'zone =' -A 1
zone = 0xffff880000020d80,
zone_idx = 2
--
zone = 0xffff8800000186c0,
zone_idx = 1
--
zone = 0xffff880000010000,
zone_idx = 0
--
zone = 0xffff880000020d80,
zone_idx = 2
--
zone = 0xffff8800000186c0,
zone_idx = 1
--
zone = 0xffff880000010000,
zone_idx = 0
crash> zone.name 0xffff880000020d80
name = 0xffffffff817cadd7 "Normal"
crash> zone.name 0xffff8800000186c0
name = 0xffffffff817cadd1 "DMA32"
crash> zone.name 0xffff880000010000
name = 0xffffffff817fb175 "DMA"
void free_pages(unsigned long addr, unsigned int order);
void free_page(addr);
/*
* Freeing function for a buddy system allocator.
*
* The concept of a buddy system is to maintain direct-mapped table
* (containing bit values) for memory blocks of various "orders".
* The bottom level table contains the map for the smallest allocatable
* units of memory (here, pages), and each level above it describes
* pairs of units from the levels below, hence, "buddies".
* At a high level, all that happens here is marking the table entry
* at the bottom level available, and propagating the changes upward
* as necessary, plus some accounting needed to play nicely with other
* parts of the VM system.
* At each level, we keep a list of pages, which are heads of continuous
* free pages of length of (1 << order) and marked with PG_buddy. Page's
* order is recorded in page_private(page) field.
* So when we are allocating or freeing one, we can derive the state of the
* other. That is, if we allocate a small block, and both were
* free, the remainder of the region must be split into blocks.
* If a block is freed, and its buddy is also free, then this
* triggers coalescing into a block of larger size.
*
* -- wli
*/
static inline void __free_one_page(struct page *page,
struct zone *zone, unsigned int order,
int migratetype)
{
...
while (order < MAX_ORDER-1) {
buddy = __page_find_buddy(page, page_idx, order);
if (!page_is_buddy(page, buddy, order))
break;
/* Our buddy is free, merge with it and move up one order. */
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
combined_idx = __find_combined_kernel/internals/index(page_idx, order);
page = page + (combined_idx - page_idx);
page_idx = combined_idx;
order++;
}
set_page_order(page, order);
...
$ head /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
nfsd_drc 35 170 112 34 1 : tunables 120 60 8 : slabdata 5 5 0
nfsd4_delegations 0 0 344 11 1 : tunables 54 27 8 : slabdata 0 0 0
nfsd4_stateids 0 0 120 32 1 : tunables 120 60 8 : slabdata 0 0 0
nfsd4_files 0 0 112 34 1 : tunables 120 60 8 : slabdata 0 0 0
...
$ slabtop
Active / Total Objects (% used) : 5808994 / 7467354 (77.8%)
Active / Total Slabs (% used) : 449532 / 449541 (100.0%)
Active / Total Caches (% used) : 108 / 187 (57.8%)
Active / Total Size (% used) : 1461810.85K / 1739611.91K (84.0%)
Minimum / Average / Maximum Object : 0.02K / 0.23K / 4096.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
2328290 1261362 54% 0.07K 43930 53 175720K selinux_inode_security
1699447 1332764 78% 0.10K 45931 37 183724K buffer_head
1456280 1250707 85% 0.78K 291256 5 1165024K ext3_inode_cache
633888 633858 99% 0.02K 4402 144 17608K avtab_node
488240 487920 99% 0.19K 24412 20 97648K dentry
...
crash> kmem -s | head
CACHE NAME OBJSIZE ALLOCATED TOTAL SLABS SSIZE
ffff8118061c1340 nfs_direct_cache 136 0 0 0 4k
ffff810c0cd31340 nfs_write_data 832 36 36 4 8k
ffff811804244300 nfs_read_data 832 32 36 4 8k
ffff810c0cd35300 nfs_inode_cache 1032 0 0 0 4k
ffff81180533b2c0 nfs_page 128 0 0 0 4k
ffff810c0d0df2c0 ip_conntrack_expect 136 0 0 0 4k
ffff8118061a3280 ip_conntrack 304 14 182 14 4k
ffff811804f1b240 ip_vs_conn 192 0 0 0 4k
ffff81180e25c200 rpc_buffers 2048 8 8 4 4k
struct kmem_cache *kmem_cache_create (const char *name,
size_t size,
size_t align,
unsigned long flags,
void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *cachep);
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
void __init fork_init(unsigned long mempages)
{
...
/* create a slab on which task_structs can be allocated */
task_struct_cachep =
kmem_cache_create("task_struct", sizeof(struct task_struct),
ARCH_MIN_TASKALIGN, SLAB_PANIC | SLAB_NOTRACK, NULL);
...
}
# define alloc_task_struct() kmem_cache_alloc(task_struct_cachep, GFP_KERNEL)
# define free_task_struct(tsk) kmem_cache_free(task_struct_cachep, (tsk))
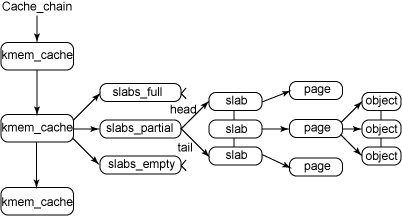
crash> sym cache_chain
ffffffff81fe3bd0 (b) cache_chain
crash> list -H ffffffff81fe3bd0 -o kmem_cache.next -s kmem_cache.name,buffer_size,num | head
ffff880113102e80
name = 0xffffffffa028ab0c "bridge_fdb_cache"
buffer_size = 64
num = 59
ffff8802bdd22e40
name = 0xffffffffa030c67d "nfs_direct_cache"
buffer_size = 200
num = 19
ffff8802bdd12e00
name = 0xffffffffa030ca02 "nfs_commit_data"
static __always_inline void *kmalloc(size_t size, gfp_t flags);
void kfree(const void *objp);
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
struct kmem_cache *cachep;
void *ret;
if (__builtin_constant_p(size)) {
int i = 0;
if (!size)
return ZERO_SIZE_PTR;
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include <linux/kmalloc_sizes.h>
#undef CACHE
return NULL;
found:
#ifdef CONFIG_ZONE_DMA
if (flags & GFP_DMA)
cachep = malloc_sizes[i].cs_dmacachep;
else
#endif
cachep = malloc_sizes[i].cs_cachep;
ret = kmem_cache_alloc_trace(size, cachep, flags);
return ret;
}
return __kmalloc(size, flags);
}
#if (PAGE_SIZE == 4096)
CACHE(32)
#endif
CACHE(64)
#if L1_CACHE_BYTES < 64
CACHE(96)
#endif
CACHE(128)
#if L1_CACHE_BYTES < 128
CACHE(192)
#endif
CACHE(256)
.....<skipped>.....
#if KMALLOC_MAX_SIZE >= 8388608
CACHE(8388608)
#endif
#if KMALLOC_MAX_SIZE >= 16777216
CACHE(16777216)
#endif
#if KMALLOC_MAX_SIZE >= 33554432
CACHE(33554432)
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
...
size-4194304(DMA) 0 0 4194304 1 1024 : tunables 1 1 0 : slabdata 0 0 0
size-4194304 0 0 4194304 1 1024 : tunables 1 1 0 : slabdata 0 0 0
...
size-1024(DMA) 0 0 1024 4 1 : tunables 54 27 8 : slabdata 0 0 0
size-1024 6974 7776 1024 4 1 : tunables 54 27 8 : slabdata 1944 1944 2
...
size-128 44781 63270 128 30 1 : tunables 120 60 8 : slabdata 2109 2109 0
size-32 379055 417312 32 112 1 : tunables 120 60 8 : slabdata 3726 3726 30
kmem_cache 214 214 32896 1 16 : tunables 8 4 0 : slabdata 214 214 0
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size);
void vfree(const void *addr);
crash> vmlist
vmlist = $5 = (struct vm_struct *) 0xffff88143fc24680
crash> vm_struct 0xffff88143fc24680
struct vm_struct {
next = 0xffff88143fc24c40,
addr = 0xffffc90000000000,
size = 8192,
flags = 1,
pages = 0x0,
nr_pages = 0,
phys_addr = 4275044352,
caller = 0xffffffff81c408f0 <hpet_enable+52>
}
crash> list 0xffff88143fc24680 -o vm_struct.next -s vm_struct.size,caller
ffff88143fc24680
size = 8192
caller = 0xffffffff81c408f0 <hpet_enable+52>
ffff88143fc24c40
size = 134221824
caller = 0xffffffff81c4fd6a <alloc_large_system_hash+362>
...
crash> list 0xffff88143fc24680 -o vm_struct.next -s vm_struct.size | grep 'size =' | awk 'BEGIN {sum =0} {sum = sum + $3} END { print "Total = ", sum, "bytes" }'
Total = 376315904 bytes
#define alloc_bootmem(x) \
__alloc_bootmem(x, SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_nopanic(x) \
__alloc_bootmem_nopanic(x, SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_pages(x) \
__alloc_bootmem(x, PAGE_SIZE, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_pages_nopanic(x) \
__alloc_bootmem_nopanic(x, PAGE_SIZE, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_node(pgdat, x) \
__alloc_bootmem_node(pgdat, x, SMP_CACHE_BYTES, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_pages_node(pgdat, x) \
__alloc_bootmem_node(pgdat, x, PAGE_SIZE, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_pages_node_nopanic(pgdat, x) \
__alloc_bootmem_node_nopanic(pgdat, x, PAGE_SIZE, __pa(MAX_DMA_ADDRESS))
#define alloc_bootmem_low(x) \
__alloc_bootmem_low(x, SMP_CACHE_BYTES, 0)
#define alloc_bootmem_low_pages(x) \
__alloc_bootmem_low(x, PAGE_SIZE, 0)
#define alloc_bootmem_low_pages_node(pgdat, x) \
__alloc_bootmem_low_node(pgdat, x, PAGE_SIZE, 0)
bootmem_data_t bootmem_node_data[MAX_NUMNODES] __initdata;
static struct list_head bdata_list __initdata = LIST_HEAD_INIT(bdata_list);
static void * __init ___alloc_bootmem_nopanic(unsigned long size,
unsigned long align,
unsigned long goal,
unsigned long limit)
{
bootmem_data_t *bdata;
void *region;
restart:
region = alloc_arch_preferred_bootmem(NULL, size, align, goal, limit);
if (region)
return region;
list_for_each_entry(bdata, &bdata_list, list) {
if (goal && bdata->node_low_pfn <= PFN_DOWN(goal))
continue;
if (limit && bdata->node_min_pfn >= PFN_DOWN(limit))
break;
region = alloc_bootmem_core(bdata, size, align, goal, limit);
if (region)
return region;
}
if (goal) {
goal = 0;
goto restart;
}
return NULL;
}
/**
* mempool_create - create a memory pool
* @min_nr: the minimum number of elements guaranteed to be
* allocated for this pool.
* @alloc_fn: user-defined element-allocation function.
* @free_fn: user-defined element-freeing function.
* @pool_data: optional private data available to the user-defined functions.
*
* this function creates and allocates a guaranteed size, preallocated
* memory pool. The pool can be used from the mempool_alloc() and mempool_free()
* functions. This function might sleep. Both the alloc_fn() and the free_fn()
* functions might sleep - as long as the mempool_alloc() function is not called
* from IRQ contexts.
*/
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn,
mempool_free_t *free_fn, void *pool_data);
/**
* mempool_destroy - deallocate a memory pool
* @pool: pointer to the memory pool which was allocated via
* mempool_create().
*
* this function only sleeps if the free_fn() function sleeps. The caller
* has to guarantee that all elements have been returned to the pool (ie:
* freed) prior to calling mempool_destroy().
*/
void mempool_destroy(mempool_t *pool);
/**
* mempool_alloc - allocate an element from a specific memory pool
* @pool: pointer to the memory pool which was allocated via
* mempool_create().
* @gfp_mask: the usual allocation bitmask.
*
* this function only sleeps if the alloc_fn() function sleeps or
* returns NULL. Note that due to preallocation, this function
* *never* fails when called from process contexts. (it might
* fail if called from an IRQ context.)
*/
void * mempool_alloc(mempool_t *pool, gfp_t gfp_mask);
/**
* mempool_free - return an element to the pool.
* @element: pool element pointer.
* @pool: pointer to the memory pool which was allocated via
* mempool_create().
*
* this function only sleeps if the free_fn() function sleeps.
*/
void mempool_free(void *element, mempool_t *pool);
/* Allocate cache for SRBs. */
srb_cachep = kmem_cache_create("qla2xxx_srbs", sizeof(srb_t), 0,
SLAB_HWCACHE_ALIGN, NULL);
/* Allocate memory for srb pool. */
ha->srb_mempool = mempool_create(SRB_MIN_REQ, mempool_alloc_slab,
mempool_free_slab, srb_cachep);
...
srb = mempool_alloc(ha->srb_mempool, GFP_ATOMIC);
...
mempool_free(srb, ha->srb_mempool);
...
mempool_free(srb, ha->srb_mempool);
/*
* A commonly used alloc and free fn.
*/
void *mempool_alloc_slab(gfp_t gfp_mask, void *pool_data)
{
struct kmem_cache *mem = pool_data;
return kmem_cache_alloc(mem, gfp_mask);
}
void mempool_free_slab(void *element, void *pool_data)
{
struct kmem_cache *mem = pool_data;
kmem_cache_free(mem, element);
}
gfs2_bh_pool = mempool_create(1024, gfs2_bh_alloc, gfs2_bh_free, NULL);
...
static void *gfs2_bh_alloc(gfp_t mask, void *data)
{
return alloc_buffer_head(mask);
}
static void gfs2_bh_free(void *ptr, void *data)
{
return free_buffer_head(ptr);
}
...
bh = mempool_alloc(gfs2_bh_pool, GFP_NOFS);
...
mempool_free(bh, gfs2_bh_pool);
...
mempool_destroy(gfs2_bh_pool);
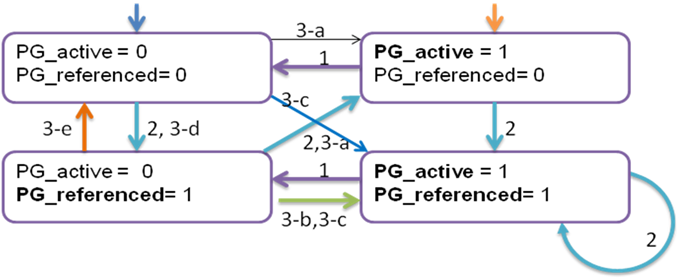
/*
* Mark a page as having seen activity.
*
* inactive,unreferenced -> inactive,referenced
* inactive,referenced -> active,unreferenced
* active,unreferenced -> active,referenced
*/
void mark_page_accessed(struct page *page)
{
if (!PageActive(page) && !PageUnevictable(page) &&
PageReferenced(page) && PageLRU(page)) {
activate_page(page);
ClearPageReferenced(page);
} else if (!PageReferenced(page)) {
SetPageReferenced(page);
}
}
static void shrink_active_list(unsigned long nr_pages,
struct mem_cgroup_zone *mz,
struct scan_control *sc,
int priority, int file)
{
...
while (!list_empty(&l_hold)) {
cond_resched();
page = lru_to_page(&l_hold);
list_del(&page->lru);
...
if (page_referenced(page, 0, sc->target_mem_cgroup,
&vm_flags)) {
nr_rotated += hpage_nr_pages(page);
/*
* Identify referenced, file-backed active pages and
* give them one more trip around the active list. So
* that executable code get better chances to stay in
* memory under moderate memory pressure. Anon pages
* are not likely to be evicted by use-once streaming
* IO, plus JVM can create lots of anon VM_EXEC pages,
* so we ignore them here.
*/
if ((vm_flags & VM_EXEC) && page_is_file_cache(page)) {
list_add(&page->lru, &l_active);
continue;
}
}
ClearPageActive(page); /* we are de-activating */
list_add(&page->lru, &l_inactive);
}
...
}
/*
* shrink_inactive_list() is a helper for shrink_zone(). It returns the number
* of reclaimed pages
*/
static unsigned long shrink_inactive_list(unsigned long max_scan,
struct mem_cgroup_zone *mz, struct scan_control *sc,
int priority, int file)
{
...
nr_taken = isolate_pages(SWAP_CLUSTER_MAX, mz, &page_list,
&nr_scan, order,
ISOLATE_INACTIVE, 0, file);
...
nr_scanned += nr_scan;
nr_freed = shrink_page_list(&page_list, sc, mz,
PAGEOUT_IO_ASYNC, priority,
&nr_dirty, &nr_writeback);
nr_reclaimed += nr_freed;
...
/*
* Put back any unfreeable pages.
*/
while (!list_empty(&page_list)) {
int lru;
page = lru_to_page(&page_list);
VM_BUG_ON(PageLRU(page));
list_del(&page->lru);
if (unlikely(!page_evictable(page, NULL))) {
spin_unlock_irq(&zone->lru_lock);
putback_lru_page(page);
spin_lock_irq(&zone->lru_lock);
continue;
}
SetPageLRU(page);
...
}
/*
* shrink_page_list() returns the number of reclaimed pages
*/
static unsigned long shrink_page_list(struct list_head *page_list,
struct scan_control *sc,
struct mem_cgroup_zone *mz,
enum pageout_io sync_writeback,
int priority,
unsigned long *ret_nr_dirty,
unsigned long *ret_nr_writeback)
{
...
}
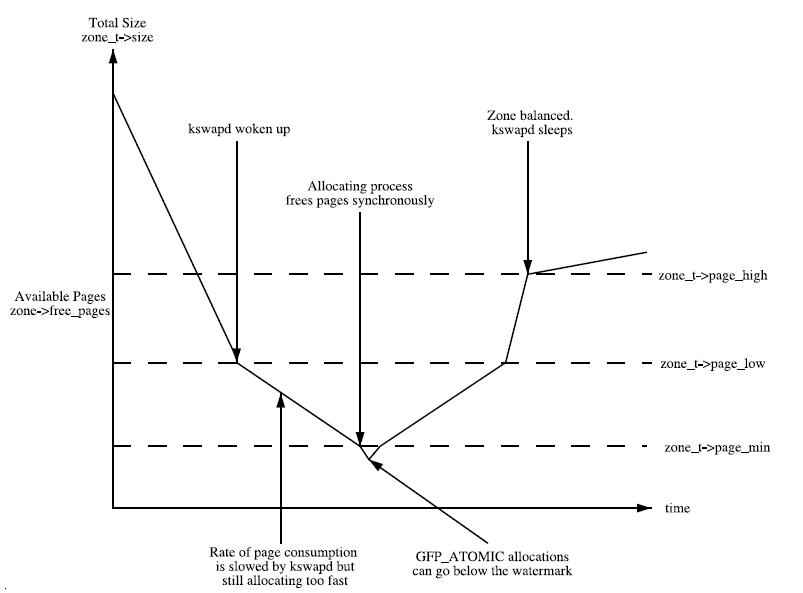
mcollectived invoked oom-killer: gfp_mask=0x201da, order=0, oom_adj=0, oom_score
_adj=0
mcollectived cpuset=/ mems_allowed=0-1
...
Node 0 DMA free:15740kB min:4kB low:4kB high:4kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:15356kB mlocked:0kB dirty:0kB writeback:0kB mapped:0kB shmem:0kB slab_reclaimable:0kB slab_unreclaimable:0kB kernel_stack:0kB pagetables:0kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? yes
lowmem_reserve[]: 0 1895 129155 129155
Node 0 DMA32 free:444928kB min:660kB low:824kB high:988kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:1940704kB mlocked:0kB dirty:0kB writeback:0kB mapped:0kB shmem:0kB slab_reclaimable:0kB slab_unreclaimable:0kB kernel_stack:0kB pagetables:0kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? yes
lowmem_reserve[]: 0 0 127260 127260
Node 0 Normal free:44604kB min:44368kB low:55460kB high:66552kB active_anon:125680892kB inactive_anon:4721304kB active_file:1764kB inactive_file:748kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:130314240kB mlocked:0kB dirty:888kB writeback:248kB mapped:2572kB shmem:8kB slab_reclaimable:56312kB slab_unreclaimable:52868kB kernel_stack:7568kB pagetables:276060kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
lowmem_reserve[]: 0 0 0 0
Node 1 Normal free:44776kB min:45072kB low:56340kB high:67608kB active_anon:127601628kB inactive_anon:3645464kB active_file:0kB inactive_file:0kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:132382720kB mlocked:0kB dirty:0kB writeback:0kB mapped:248kB shmem:0kB slab_reclaimable:17736kB slab_unreclaimable:33500kB kernel_stack:1480kB pagetables:289524kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:3920 all_unreclaimable? no
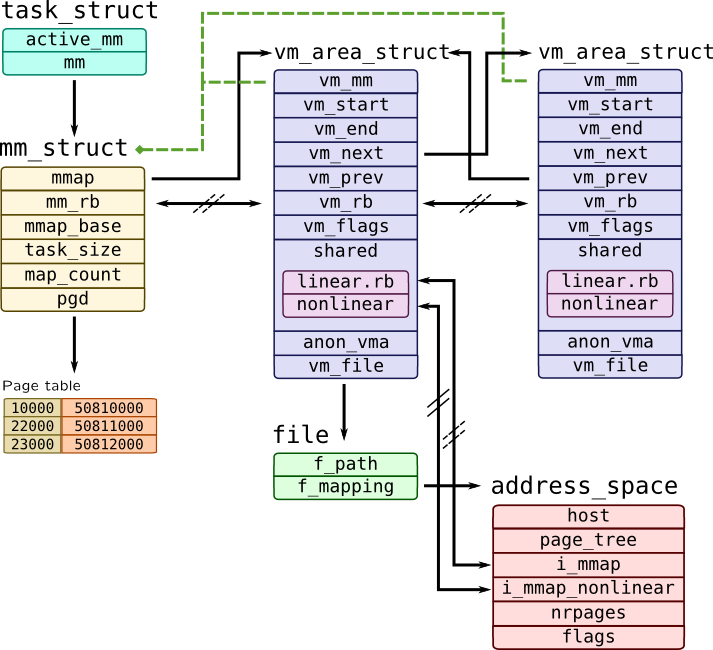
crash> task_struct.mm
struct task_struct {
[1152] struct mm_struct *mm;
}
crash> mm_struct
struct mm_struct {
struct vm_area_struct *mmap;
struct rb_root mm_rb;
struct vm_area_struct *mmap_cache;
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
unsigned long (*get_unmapped_exec_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
void (*unmap_area)(struct mm_struct *, unsigned long);
unsigned long mmap_base;
unsigned long task_size;
unsigned long cached_hole_size;
unsigned long free_area_cache;
pgd_t *pgd;
atomic_t mm_users;
atomic_t mm_count;
int map_count;
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock;
struct list_head mmlist;
mm_counter_t _file_rss;
mm_counter_t _anon_rss;
mm_counter_t _swap_usage;
unsigned long hiwater_rss;
unsigned long hiwater_vm;
unsigned long total_vm;
unsigned long locked_vm;
unsigned long shared_vm;
unsigned long exec_vm;
unsigned long stack_vm;
unsigned long reserved_vm;
unsigned long def_flags;
unsigned long nr_ptes;
unsigned long start_code;
unsigned long end_code;
unsigned long start_data;
unsigned long end_data;
unsigned long start_brk;
unsigned long brk;
unsigned long start_stack;
unsigned long arg_start;
unsigned long arg_end;
unsigned long env_start;
unsigned long env_end;
unsigned long saved_auxv[44];
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
mm_context_t context;
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags;
struct core_state *core_state;
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
struct task_struct *owner;
struct file *exe_file;
unsigned long num_exe_file_vmas;
struct mmu_notifier_mm *mmu_notifier_mm;
pgtable_t pmd_huge_pte;
union {
unsigned long rh_reserved_aux;
atomic_t oom_disable_count;
};
unsigned long shlib_base;
}
crash> set 123
PID: 123
COMMAND: "khungtaskd"
TASK: ffff88043370d520 [THREAD_INFO: ffff880433740000]
CPU: 2
STATE: TASK_INTERRUPTIBLE
crash> task_struct.mm ffff88043370d520
mm = 0x0
crash> set 32758
PID: 32758
COMMAND: "sshd"
TASK: ffff880431e0c040 [THREAD_INFO: ffff88010f0d8000]
CPU: 3
STATE: TASK_INTERRUPTIBLE
crash> task_struct.mm ffff880431e0c040
mm = 0xffff880435451480
static inline unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
{
unsigned long ret = -EINVAL;
if ((offset + PAGE_ALIGN(len)) < offset)
goto out;
if (!(offset & ~PAGE_MASK))
ret = do_mmap_pgoff(file, addr, len, prot, flag, offset >> PAGE_SHIFT);
out:
return ret;
}
crash> mm_struct.mmap
struct mm_struct {
[0] struct vm_area_struct *mmap;
}
crash> mm_struct.mmap,mm_rb 0xffff880435451480
mmap = 0xffff880436c1e2d8
mm_rb = {
rb_node = 0xffff88026c189180
}
crash> list 0xffff880436c1e2d8 -o vm_area_struct.vm_next -s vm_area_struct.vm_start,vm_end,vm_file,vm_flags,vm_ops | head -n 20
ffff880436c1e2d8
vm_start = 0x7fb4d2666000
vm_end = 0x7fb4d2707000
vm_file = 0xffff88029a34f7c0
vm_flags = 0x8000075
vm_ops = 0xffffffffa00d6f80 <ext4_file_vm_ops>
ffff880436c1e9e0
vm_start = 0x7fb4d2707000
vm_end = 0x7fb4d2806000
vm_file = 0xffff88029a34f7c0
vm_flags = 0x8000070
vm_ops = 0xffffffffa00d6f80 <ext4_file_vm_ops>
ffff880436c1e468
vm_start = 0x7fb4d2806000
vm_end = 0x7fb4d280a000
vm_file = 0xffff88029a34f7c0
vm_flags = 0x8100073
vm_ops = 0xffffffffa00d6f80 <ext4_file_vm_ops>
ffff880436c1e210
vm_start = 0x7fb4d280a000
crash> vm | head
PID: 32758 TASK: ffff880431e0c040 CPU: 3 COMMAND: "sshd"
MM PGD RSS TOTAL_VM
ffff880435451480 ffff880162e6c000 4724k 107364k
VMA START END FLAGS FILE
ffff880436c1e2d8 7fb4d2666000 7fb4d2707000 8000075 /lib64/libnss_uxauth.so.2
ffff880436c1e9e0 7fb4d2707000 7fb4d2806000 8000070 /lib64/libnss_uxauth.so.2
ffff880436c1e468 7fb4d2806000 7fb4d280a000 8100073 /lib64/libnss_uxauth.so.2
ffff880436c1e210 7fb4d280a000 7fb4d280e000 100073
ffff880436c1e5f8 7fb4d280e000 7fb4d294e000 80000fb /dev/zero
ffff8804326013e0 7fb4d294e000 7fb4d2952000 8000075 /lib64/security/pam_limits.s
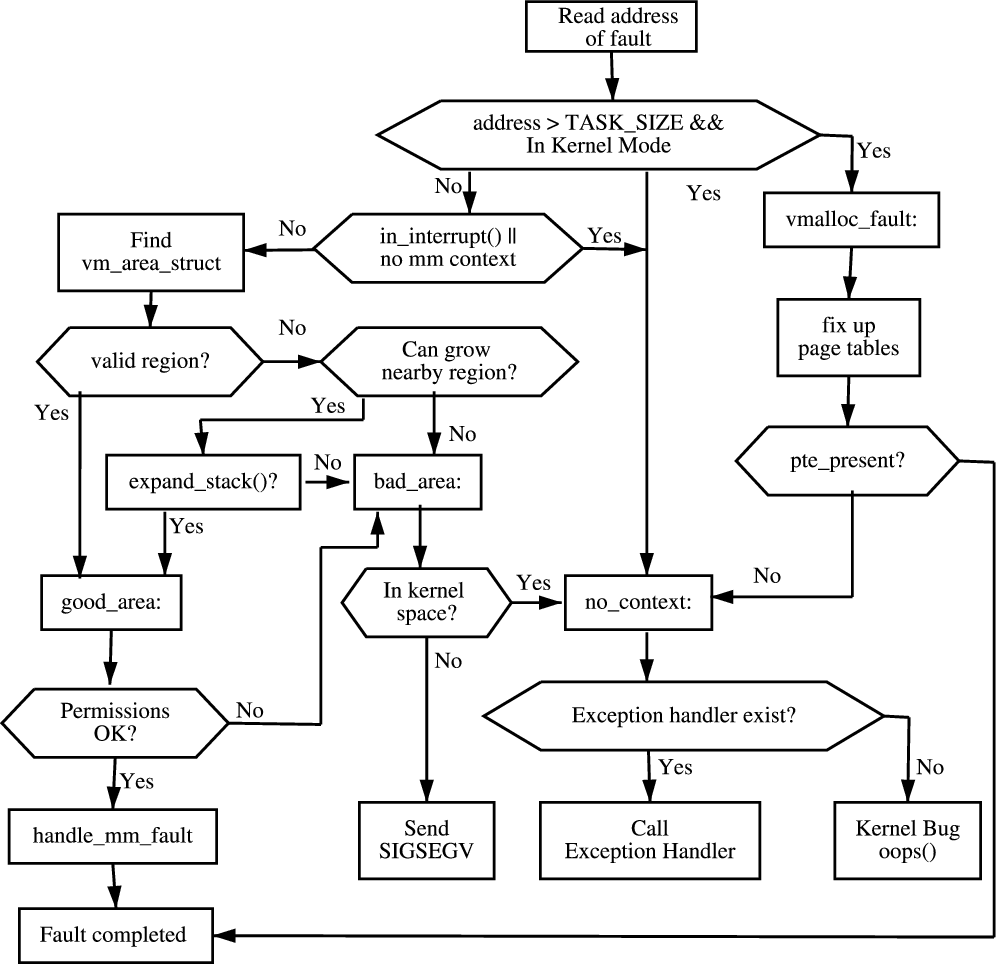
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
dotraplinkage void __kprobes
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address;
/* Get the faulting address: */
address = read_cr2();
__do_page_fault(regs, address, error_code);
if (!user_mode(regs))
trace_mm_kernel_pagefault(current, address, regs);
}
/*
* Page fault error code bits:
*
* bit 0 == 0: no page found 1: protection fault
* bit 1 == 0: read access 1: write access
* bit 2 == 0: kernel-mode access 1: user-mode access
* bit 3 == 1: use of reserved bit detected
* bit 4 == 1: fault was an instruction fetch
*/
enum x86_pf_error_code {
PF_PROT = 1 << 0,
PF_WRITE = 1 << 1,
PF_USER = 1 << 2,
PF_RSVD = 1 << 3,
PF_INSTR = 1 << 4,
};
static inline void __do_page_fault(struct pt_regs *regs, unsigned long address, unsigned long error_code);