Block Device Driver
What’s block device driver ?
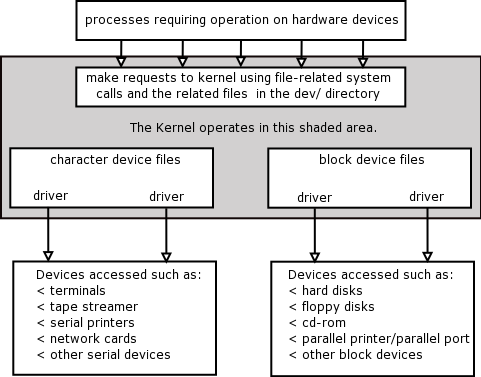
- In general, filesystems are locating on top of the block device such as hard disk, CD-ROM, USB memory stick, RAM disk, etc.
- Block device driver needs to handle request queue which is handling block data for read/write
- Each block device has ‘gendisk’ to represent the device stats
- Block device has concept of partitioning
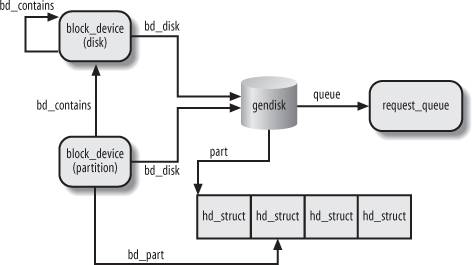
- structure ‘gendisk’
struct gendisk {
/* major, first_minor and minors are input parameters only,
* don't use directly. Use disk_devt() and disk_max_parts().
*/
int major; /* major number of driver */
int first_minor;
int minors; /* maximum number of minors, =1 for
* disks that can't be partitioned. */
char disk_name[DISK_NAME_LEN]; /* name of major driver */
char *(*devnode)(struct gendisk *gd, umode_t *mode);
unsigned int events; /* supported events */
unsigned int async_events; /* async events, subset of all */
/* Array of pointers to partitions indexed by partno.
* Protected with matching bdev lock but stat and other
* non-critical accesses use RCU. Always access through
* helpers.
*/
struct disk_part_tbl __rcu *part_tbl;
struct hd_struct part0;
const struct block_device_operations *fops;
struct request_queue *queue;
void *private_data;
int flags;
struct device *driverfs_dev; // FIXME: remove
struct kobject *slave_dir;
struct timer_rand_state *random;
atomic_t sync_io; /* RAID */
struct disk_events *ev;
#ifdef CONFIG_BLK_DEV_INTEGRITY
struct blk_integrity *integrity;
#endif
int node_id;
};
- gendisk contains
- ‘hd_struct’ which contains detailed information about disk’s number of sylinders, sectors, etc.
- request_queue which handles block data request from the upper layer
- ‘fops’ contains the operations related to the block device
struct hd_struct {
sector_t start_sect;
/*
* nr_sects is protected by sequence counter. One might extend a
* partition while IO is happening to it and update of nr_sects
* can be non-atomic on 32bit machines with 64bit sector_t.
*/
sector_t nr_sects;
seqcount_t nr_sects_seq;
sector_t alignment_offset;
unsigned int discard_alignment;
struct device __dev;
struct kobject *holder_dir;
int policy, partno;
struct partition_meta_info *info;
#ifdef CONFIG_FAIL_MAKE_REQUEST
int make_it_fail;
#endif
unsigned long stamp;
atomic_t in_flight[2];
#ifdef CONFIG_SMP
struct disk_stats __percpu *dkstats;
#else
struct disk_stats dkstats;
#endif
atomic_t ref;
struct rcu_head rcu_head;
};
Registering a new block device driver
- To register a block device driver, needs to allocate a major number with a name
/**
* register_blkdev - register a new block device
*
* @major: the requested major device number [1..255]. If @major=0, try to
* allocate any unused major number.
* @name: the name of the new block device as a zero terminated string
*
* The @name must be unique within the system.
*
* The return value depends on the @major input parameter.
* - if a major device number was requested in range [1..255] then the
* function returns zero on success, or a negative error code
* - if any unused major number was requested with @major=0 parameter
* then the return value is the allocated major number in range
* [1..255] or a negative error code otherwise
*/
int register_blkdev(unsigned int major, const char *name);
void unregister_blkdev(unsigned int major, const char *name);
- Once it’s properly allocated, needs to allocate/fill gendisk and register it.
struct gendisk *alloc_disk(int minors);
/**
* add_disk - add partitioning information to kernel list
* @disk: per-device partitioning information
*
* This function registers the partitioning information in @disk
* with the kernel.
*
* FIXME: error handling
*/
void add_disk(struct gendisk *disk);
void del_gendisk(struct gendisk *disk);
struct kobject *get_disk(struct gendisk *disk);
void put_disk(struct gendisk *disk);
- Let’s see how it’s implemented in ‘hd’ (legacy hard disk driver).
static int __init hd_init(void)
{
int drive;
if (register_blkdev(HD_MAJOR, "hd"))
return -1;
hd_queue = blk_init_queue(do_hd_request, &hd_lock);
if (!hd_queue) {
unregister_blkdev(HD_MAJOR, "hd");
return -ENOMEM;
}
blk_queue_max_hw_sectors(hd_queue, 255);
init_timer(&device_timer);
device_timer.function = hd_times_out;
blk_queue_logical_block_size(hd_queue, 512);
...
for (drive = 0 ; drive < NR_HD ; drive++) {
struct gendisk *disk = alloc_disk(64);
struct hd_i_struct *p = &hd_info[drive];
if (!disk)
goto Enomem;
disk->major = HD_MAJOR;
disk->first_minor = drive << 6;
disk->fops = &hd_fops;
sprintf(disk->disk_name, "hd%c", 'a'+drive);
disk->private_data = p;
set_capacity(disk, p->head * p->sect * p->cyl);
disk->queue = hd_queue;
p->unit = drive;
hd_gendisk[drive] = disk;
printk("%s: %luMB, CHS=%d/%d/%d\n",
disk->disk_name, (unsigned long)get_capacity(disk)/2048,
p->cyl, p->head, p->sect);
}
if (request_irq(HD_IRQ, hd_interrupt, IRQF_DISABLED, "hd", NULL)) {
printk("hd: unable to get IRQ%d for the hard disk driver\n",
HD_IRQ);
goto out1;
}
if (!request_region(HD_DATA, 8, "hd")) {
printk(KERN_WARNING "hd: port 0x%x busy\n", HD_DATA);
goto out2;
}
if (!request_region(HD_CMD, 1, "hd(cmd)")) {
printk(KERN_WARNING "hd: port 0x%x busy\n", HD_CMD);
goto out3;
}
/* Let them fly */
for (drive = 0; drive < NR_HD; drive++)
add_disk(hd_gendisk[drive]);
return 0;
out3:
release_region(HD_DATA, 8);
out2:
free_irq(HD_IRQ, NULL);
out1:
for (drive = 0; drive < NR_HD; drive++)
put_disk(hd_gendisk[drive]);
NR_HD = 0;
out:
del_timer(&device_timer);
unregister_blkdev(HD_MAJOR, "hd");
blk_cleanup_queue(hd_queue);
return -1;
Enomem:
while (drive--)
put_disk(hd_gendisk[drive]);
goto out;
}
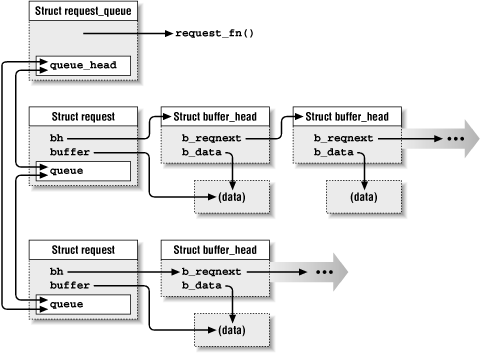
Handling request
- ‘request’ is a unit to request read/write into the block device
struct request_queue {
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
int nr_rqs[2]; /* # allocated [a]sync rqs */
int nr_rqs_elvpriv; /* # allocated rqs w/ elvpriv */
/*
* If blkcg is not used, @q->root_rl serves all requests. If blkcg
* is used, root blkg allocates from @q->root_rl and all other
* blkgs from their own blkg->rl. Which one to use should be
* determined using bio_request_list().
*/
struct request_list root_rl;
request_fn_proc *request_fn;
make_request_fn *make_request_fn;
prep_rq_fn *prep_rq_fn;
merge_bvec_fn *merge_bvec_fn;
...
unsigned int nr_queues;
...
};
struct request {
#ifdef __GENKSYMS__
union {
struct list_head queuelist;
struct llist_node ll_list;
};
#else
struct list_head queuelist;
#endif
union {
struct call_single_data csd;
RH_KABI_REPLACE(struct work_struct mq_flush_work,
unsigned long fifo_time)
};
struct request_queue *q;
struct blk_mq_ctx *mq_ctx;
...
/* the following two fields are internal, NEVER access directly */
unsigned int __data_len; /* total data len */
sector_t __sector; /* sector cursor */
struct bio *bio;
struct bio *biotail;
...
struct gendisk *rq_disk;
struct hd_struct *part;
unsigned long start_time;
...
void *special; /* opaque pointer available for LLD use */
char *buffer; /* kaddr of the current segment if available */
...
/*
* completion callback.
*/
rq_end_io_fn *end_io;
void *end_io_data;
/* for bidi */
struct request *next_rq;
};
- blk_init_queue() and blk_cleanup_queue : prepare a request queue and cleanup
/**
* blk_init_queue - prepare a request queue for use with a block device
* @rfn: The function to be called to process requests that have been
* placed on the queue.
* @lock: Request queue spin lock
*
* Description:
* If a block device wishes to use the standard request handling procedures,
* which sorts requests and coalesces adjacent requests, then it must
* call blk_init_queue(). The function @rfn will be called when there
* are requests on the queue that need to be processed. If the device
* supports plugging, then @rfn may not be called immediately when requests
* are available on the queue, but may be called at some time later instead.
* Plugged queues are generally unplugged when a buffer belonging to one
* of the requests on the queue is needed, or due to memory pressure.
*
* @rfn is not required, or even expected, to remove all requests off the
* queue, but only as many as it can handle at a time. If it does leave
* requests on the queue, it is responsible for arranging that the requests
* get dealt with eventually.
*
* The queue spin lock must be held while manipulating the requests on the
* request queue; this lock will be taken also from interrupt context, so irq
* disabling is needed for it.
*
* Function returns a pointer to the initialized request queue, or %NULL if
* it didn't succeed.
*
* Note:
* blk_init_queue() must be paired with a blk_cleanup_queue() call
* when the block device is deactivated (such as at module unload).
**/
struct request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock);
/**
* blk_cleanup_queue - shutdown a request queue
* @q: request queue to shutdown
*
* Mark @q DYING, drain all pending requests, mark @q DEAD, destroy and
* put it. All future requests will be failed immediately with -ENODEV.
*/
void blk_cleanup_queue(struct request_queue *q);
- blk_fetch_request() : fetch a request from a request queue
/**
* blk_fetch_request - fetch a request from a request queue
* @q: request queue to fetch a request from
*
* Description:
* Return the request at the top of @q. The request is started on
* return and LLD can start processing it immediately.
*
* Return:
* Pointer to the request at the top of @q if available. Null
* otherwise.
*
* Context:
* queue_lock must be held.
*/
struct request *blk_fetch_request(struct request_queue *q);
- request sector and size related functions
/*
* blk_rq_pos() : the current sector
* blk_rq_bytes() : bytes left in the entire request
* blk_rq_cur_bytes() : bytes left in the current segment
* blk_rq_err_bytes() : bytes left till the next error boundary
* blk_rq_sectors() : sectors left in the entire request
* blk_rq_cur_sectors() : sectors left in the current segment
* blk_rq_err_sectors() : sectors left till the next error boundary
*/
boolean rq_data_dir(rq) : read/write mode. return value 0 : read, 1: write
- Finishing up the requests
/**
* blk_end_request - Helper function for drivers to complete the request.
* @rq: the request being processed
* @error: %0 for success, < %0 for error
* @nr_bytes: number of bytes to complete
*
* Description:
* Ends I/O on a number of bytes attached to @rq.
* If @rq has leftover, sets it up for the next range of segments.
*
* Return:
* %false - we are done with this request
* %true - still buffers pending for this request
**/
bool blk_end_request(struct request *rq, int error, unsigned int nr_bytes);
/**
* blk_end_request_all - Helper function for drives to finish the request.
* @rq: the request to finish
* @error: %0 for success, < %0 for error
*
* Description:
* Completely finish @rq.
*/
void blk_end_request_all(struct request *rq, int error);
- Example: sbd.c
/*
* A sample, extra-simple block driver. Updated for kernel 2.6.31.
*
* (C) 2003 Eklektix, Inc.
* (C) 2010 Pat Patterson <pat at superpat dot com>
* Redistributable under the terms of the GNU GPL.
*/
/*
* This code was from the below website
* http://blog.superpat.com/2010/05/04/a-simple-block-driver-for-linux-kernel-2-6-31/
*/
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/init.h>
#include <linux/kernel.h> /* printk() */
#include <linux/fs.h> /* everything... */
#include <linux/errno.h> /* error codes */
#include <linux/types.h> /* size_t */
#include <linux/vmalloc.h>
#include <linux/genhd.h>
#include <linux/blkdev.h>
#include <linux/hdreg.h>
MODULE_LICENSE("Dual BSD/GPL");
static int major_num = 0;
module_param(major_num, int, 0);
static int logical_block_size = 512;
module_param(logical_block_size, int, 0);
static int nsectors = 1024; /* How big the drive is */
module_param(nsectors, int, 0);
/*
* We can tweak our hardware sector size, but the kernel talks to us
* in terms of small sectors, always.
*/
#define KERNEL_SECTOR_SIZE 512
/*
* Our request queue.
*/
static struct request_queue *Queue;
/*
* The internal representation of our device.
*/
static struct sbd_device {
unsigned long size;
spinlock_t lock;
u8 *data;
struct gendisk *gd;
} Device;
/*
* Handle an I/O request.
*/
static void sbd_transfer(struct sbd_device *dev, sector_t sector,
unsigned long nsect, char *buffer, int write) {
unsigned long offset = sector * logical_block_size;
unsigned long nbytes = nsect * logical_block_size;
if ((offset + nbytes) > dev->size) {
printk (KERN_NOTICE "sbd: Beyond-end write (%ld %ld)\n", offset, nbytes);
return;
}
if (write)
memcpy(dev->data + offset, buffer, nbytes);
else
memcpy(buffer, dev->data + offset, nbytes);
}
static void sbd_request(struct request_queue *q) {
struct request *req;
req = blk_fetch_request(q);
while (req != NULL) {
// blk_fs_request() was removed in 2.6.36 - many thanks to
// Christian Paro for the heads up and fix...
//if (!blk_fs_request(req)) {
if (req == NULL || (req->cmd_type != REQ_TYPE_FS)) {
printk (KERN_NOTICE "Skip non-CMD request\n");
__blk_end_request_all(req, -EIO);
continue;
}
sbd_transfer(&Device, blk_rq_pos(req), blk_rq_cur_sectors(req),
req->buffer, rq_data_dir(req));
if ( ! __blk_end_request_cur(req, 0) ) {
req = blk_fetch_request(q);
}
}
}
/*
* The HDIO_GETGEO ioctl is handled in blkdev_ioctl(), which
* calls this. We need to implement getgeo, since we can't
* use tools such as fdisk to partition the drive otherwise.
*/
int sbd_getgeo(struct block_device * block_device, struct hd_geometry * geo) {
long size;
/* We have no real geometry, of course, so make something up. */
size = Device.size * (logical_block_size / KERNEL_SECTOR_SIZE);
geo->cylinders = (size & ~0x3f) >> 6;
geo->heads = 4;
geo->sectors = 16;
geo->start = 0;
return 0;
}
/*
* The device operations structure.
*/
static struct block_device_operations sbd_ops = {
.owner = THIS_MODULE,
.getgeo = sbd_getgeo
};
static int __init sbd_init(void) {
/*
* Set up our internal device.
*/
Device.size = nsectors * logical_block_size;
spin_lock_init(&Device.lock);
Device.data = vmalloc(Device.size);
if (Device.data == NULL)
return -ENOMEM;
/*
* Get a request queue.
*/
Queue = blk_init_queue(sbd_request, &Device.lock);
if (Queue == NULL)
goto out;
blk_queue_logical_block_size(Queue, logical_block_size);
/*
* Get registered.
*/
major_num = register_blkdev(major_num, "sbd");
if (major_num < 0) {
printk(KERN_WARNING "sbd: unable to get major number\n");
goto out;
}
/*
* And the gendisk structure.
*/
Device.gd = alloc_disk(16);
if (!Device.gd)
goto out_unregister;
Device.gd->major = major_num;
Device.gd->first_minor = 0;
Device.gd->fops = &sbd_ops;
Device.gd->private_data = &Device;
strcpy(Device.gd->disk_name, "sbd0");
set_capacity(Device.gd, nsectors);
Device.gd->queue = Queue;
add_disk(Device.gd);
return 0;
out_unregister:
unregister_blkdev(major_num, "sbd");
out:
vfree(Device.data);
return -ENOMEM;
}
static void __exit sbd_exit(void)
{
del_gendisk(Device.gd);
put_disk(Device.gd);
unregister_blkdev(major_num, "sbd");
blk_cleanup_queue(Queue);
vfree(Device.data);
}
module_init(sbd_init);
module_exit(sbd_exit);
- How to run
$ insmod sbd.ko
$ fdisk /dev/sbd0
$ mkfs /dev/sbd0p1
$ mount /dev/sbd0p1 /mnt
$ echo "Test" > /mnt/file1
$ cat /mnt/file1
$ crash
crash> dev -d
MAJOR GENDISK NAME REQUEST_QUEUE TOTAL ASYNC SYNC DRV
8 ffff8802316d8000 sda ffff88022fa38000 0 0 0 0
11 ffff88023176e800 sr0 ffff8802316b0000 0 0 0 0
253 ffff88023175c800 dm-0 ffff88022ec68000 0 0 0 0
253 ffff8802317a7000 dm-1 ffff8802316b0850 0 0 0 0
252 ffff8801d4b2d400 sbd0 ffff88022ec690a0 0 0 0 0
crash> request_queue.request_fn ffff88022ec690a0
request_fn = 0xffffffffa07b0050
crash> sym 0xffffffffa07b0050
ffffffffa07b0050 (t) sbd_request [sbd]
$ umount /mnt
$ rmmod sbd
I/O scheduler
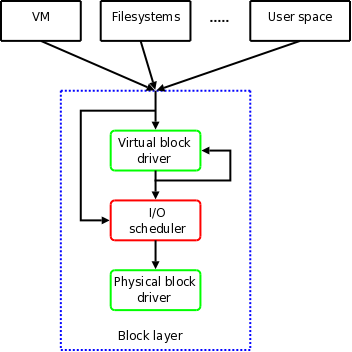
- I/O scheduler can be set during the boot or by changing the properties for each block devices.
- Boot time change can be done with using ‘elevator=’
char chosen_elevator[ELV_NAME_MAX];
EXPORT_SYMBOL(chosen_elevator);
static int __init elevator_setup(char *str)
{
/*
* Be backwards-compatible with previous kernels, so users
* won't get the wrong elevator.
*/
strncpy(chosen_elevator, str, sizeof(chosen_elevator) - 1);
return 1;
}
__setup("elevator=", elevator_setup);
- scheduler (elevator) will be handled by related module, so, this needs to be loaded.
/* called during boot to load the elevator chosen by the elevator param */
void __init load_default_elevator_module(void)
{
struct elevator_type *e;
if (!chosen_elevator[0])
return;
spin_lock(&elv_list_lock);
e = elevator_find(chosen_elevator);
spin_unlock(&elv_list_lock);
if (!e)
request_module("%s-iosched", chosen_elevator);
}
static struct elevator_type *elevator_find(const char *name)
{
struct elevator_type *e;
list_for_each_entry(e, &elv_list, list) {
if (!strcmp(e->elevator_name, name))
return e;
}
return NULL;
}
- You can find scheduler list by running the below on vmcore.
crash> list -H elv_list -l elevator_type.list -s elevator_type.elevator_name
ffffffff81a6cde8
elevator_name = "noop\000\000\000\000\000\000\000\000\000\000\000"
ffffffff81a6cee8
elevator_name = "deadline\000\000\000\000\000\000\000"
ffffffff81a6d0a8
elevator_name = "cfq\000\000\000\000\000\000\000\000\000\000\000\000"
- These schedulers are loaded by calling ‘elv_register()’
int elv_register(struct elevator_type *e)
{
char *def = "";
/* create icq_cache if requested */
if (e->icq_size) {
if (WARN_ON(e->icq_size < sizeof(struct io_cq)) ||
WARN_ON(e->icq_align < __alignof__(struct io_cq)))
return -EINVAL;
snprintf(e->icq_cache_name, sizeof(e->icq_cache_name),
"%s_io_cq", e->elevator_name);
e->icq_cache = kmem_cache_create(e->icq_cache_name, e->icq_size,
e->icq_align, 0, NULL);
if (!e->icq_cache)
return -ENOMEM;
}
/* register, don't allow duplicate names */
spin_lock(&elv_list_lock);
if (elevator_find(e->elevator_name)) {
spin_unlock(&elv_list_lock);
if (e->icq_cache)
kmem_cache_destroy(e->icq_cache);
return -EBUSY;
}
list_add_tail(&e->list, &elv_list);
spin_unlock(&elv_list_lock);
/* print pretty message */
if (!strcmp(e->elevator_name, chosen_elevator) ||
(!*chosen_elevator &&
!strcmp(e->elevator_name, CONFIG_DEFAULT_IOSCHED)))
def = " (default)";
printk(KERN_INFO "io scheduler %s registered%s\n", e->elevator_name,
def);
return 0;
}
- Default schedulers are all registered during the boot and printing the below messages.
crash> log | grep scheduler
[ 10.319690] io scheduler noop registered
[ 10.319697] io scheduler deadline registered (default)
[ 10.319719] io scheduler cfq registered
- Each scheduler named after it’s file name such as ‘cfq-iosched.c’.
- Actual block request needs to go through the elevator operations.
How application’s write goes into the block device.
- Application’s ‘write()’ call goes into ‘sys_write()’ in the kernel
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
- VFS’s ‘vfs_write()’ is called
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
...
ret = rw_verify_area(WRITE, file, pos, count);
if (ret >= 0) {
..
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos);
else
ret = do_sync_write(file, buf, count, pos);
...
}
return ret;
}
- To get ‘file->f_op->write’, it needs to traverse the path. In the case of ext4, it’ll be like below.
crash> mount | grep "root_lv"
ffff8820249b4e00 ffff881021e97800 ext4 /dev/mapper/rootvg-root_lv /
crash> super_block.s_op ffff881021e97800
s_op = 0xffffffffa02a6480 <ext4_sops>
crash> super_block.s_root ffff881021e97800
s_root = 0xffff8820255df080
crash> dentry.d_inode 0xffff8820255df080
d_inode = 0xffff881024af84c8
crash> inode.i_fop 0xffff881024af84c8
i_fop = 0xffffffffa02a4100 <ext4_dir_operations>
crash> inode.i_op,i_fop 0xffff881024af84c8
i_op = 0xffffffffa02a4e80 <ext4_dir_inode_operations>
i_fop = 0xffffffffa02a4100 <ext4_dir_operations>
crash> inode_operations.lookup 0xffffffffa02a4e80
lookup = 0xffffffffa02607f0
crash> sym 0xffffffffa02607f0
ffffffffa02607f0 (t) ext4_lookup [ext4] /usr/src/debug/kernel-3.10.0-327.el7/linux-3.10.0-327.el7.x86_64/fs/ext4/namei.c: 1413
- ‘ext4_lookup’ is actually finding an inode and set the proper operations.
static struct dentry *ext4_lookup(struct inode *dir, struct dentry *dentry, unsigned int flags)
{
...
inode = ext4_iget_normal(dir->i_sb, ino);
...
}
struct inode *ext4_iget_normal(struct super_block *sb, unsigned long ino)
{
if (ino < EXT4_FIRST_INO(sb) && ino != EXT4_ROOT_INO)
return ERR_PTR(-EIO);
return ext4_iget(sb, ino);
}
struct inode *ext4_iget(struct super_block *sb, unsigned long ino)
{
...
if (S_ISREG(inode->i_mode)) {
inode->i_op = &ext4_file_inode_operations;
inode->i_fop = &ext4_file_operations;
ext4_set_aops(inode);
} else if (S_ISDIR(inode->i_mode)) {
inode->i_op = &ext4_dir_inode_operations.ops;
inode->i_fop = &ext4_dir_operations;
inode->i_flags |= S_IOPS_WRAPPER;
...
}
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read = do_sync_read,
.write = do_sync_write,
.aio_read = generic_file_aio_read,
.aio_write = ext4_file_write,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.splice_read = generic_file_splice_read,
.splice_write = generic_file_splice_write,
.fallocate = ext4_fallocate,
};
crash> sym ext4_file_operations
ffffffffa02a4300 (r) ext4_file_operations [ext4]
crash> struct file_operations.write,aio_write ffffffffa02a4300
write = 0xffffffff811ddd20 <do_sync_write>
aio_write = 0xffffffffa024eab0 <ext4_file_write>
ssize_t do_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{
...
ret = filp->f_op->aio_write(&kiocb, &iov, 1, kiocb.ki_pos);
...
return ret;
}
- ‘ext4_file_write()’ is actually doing ‘write’ operation
static ssize_t
ext4_file_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos)
{
struct inode *inode = file_inode(iocb->ki_filp);
...
if (unlikely(io_is_direct(iocb->ki_filp)))
ret = ext4_file_dio_write(iocb, iov, nr_segs, pos);
else
ret = generic_file_aio_write(iocb, iov, nr_segs, pos);
return ret;
}
ssize_t generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos)
{
...
ret = __generic_file_aio_write(iocb, iov, nr_segs, &iocb->ki_pos);
...
}
return ret;
}
ssize_t __generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t *ppos)
{
...
if (io_is_direct(file)) {
...
written = generic_file_direct_write(iocb, iov, &nr_segs, pos,
ppos, count, ocount);
...
} else {
written = generic_file_buffered_write(iocb, iov, nr_segs,
pos, ppos, count, written);
}
out:
...
return written ? written : err;
}
ssize_t
generic_file_buffered_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos, loff_t *ppos,
size_t count, ssize_t written)
{
...
status = generic_perform_write(file, &i, pos);
...
return written ? written : status;
}
ssize_t
generic_file_buffered_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos, loff_t *ppos,
size_t count, ssize_t written)
{
struct file *file = iocb->ki_filp;
ssize_t status;
struct iov_iter i;
iov_iter_init(&i, iov, nr_segs, count, written);
status = generic_perform_write(file, &i, pos);
if (likely(status >= 0)) {
written += status;
*ppos = pos + status;
}
return written ? written : status;
}
EXPORT_SYMBOL(generic_file_buffered_write);
static ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
struct address_space *mapping = file->f_mapping;
const struct address_space_operations *a_ops = mapping->a_ops;
....
do {
...
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
...
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
...
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
...
} while (iov_iter_count(i));
return written ? written : status;
}
- Actual file write operations are happened using ‘a_ops->write_beging’ and ‘a_ops->write_end’.
crash> files
PID: 5485 TASK: ffff88101957b980 CPU: 17 COMMAND: "python"
ROOT: / CWD: /home/seeproxy/seeproxy
FD FILE DENTRY INODE TYPE PATH
0 ffff882027751000 ffff882028808240 ffff8820287a0850 CHR /dev/null
1 ffff882027750e00 ffff882028808240 ffff8820287a0850 CHR /dev/null
2 ffff882027750d00 ffff882028808240 ffff8820287a0850 CHR /dev/null
3 ffff882024f42b00 ffff882022486d80 ffff882020c88cf8 REG /home/seeproxy/seeproxy/logs/seeproxy.log
crash> struct file.f_mapping ffff882024f42b00
f_mapping = 0xffff882020c88e48
crash> address_space.a_ops 0xffff882020c88e48
a_ops = 0xffffffffa02a47e0 <ext4_da_aops>
crash> address_space_operations.write_begin,write_end 0xffffffffa02a47e0
write_begin = 0xffffffffa0259570
write_end = 0xffffffffa025a0b0
crash> sym 0xffffffffa0259570
ffffffffa0259570 (t) ext4_da_write_begin [ext4] /usr/src/debug/kernel-3.10.0-327.el7/linux-3.10.0-327.el7.x86_64/fs/ext4/inode.c: 2509
crash> sym 0xffffffffa025a0b0
ffffffffa025a0b0 (t) ext4_da_write_end [ext4] /usr/src/debug/kernel-3.10.0-327.el7/linux-3.10.0-327.el7.x86_64/fs/ext4/inode.c: 2625
static int ext4_da_write_begin(struct file *file, struct address_space *mapping,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata)
{
...
ret = __block_write_begin(page, pos, len, ext4_da_get_block_prep);
...
}
- block device write request is happening in ‘__block_write_begin()’
int __block_write_begin(struct page *page, loff_t pos, unsigned len,
get_block_t *get_block)
{
...
struct inode *inode = page->mapping->host;
...
head = create_page_buffers(page, inode, 0);
blocksize = head->b_size;
bbits = block_size_bits(blocksize);
block = (sector_t)page->index << (PAGE_CACHE_SHIFT - bbits);
for(bh = head, block_start = 0; bh != head || !block_start;
block++, block_start=block_end, bh = bh->b_this_page) {
block_end = block_start + blocksize;
...
if (!buffer_uptodate(bh) && !buffer_delay(bh) &&
!buffer_unwritten(bh) &&
(block_start < from || block_end > to)) {
ll_rw_block(READ, 1, &bh); <--- Actual write happens here
*wait_bh++=bh;
}
}
...
}
- ‘ll_rw_block()’ is submit the buffer_head to the lower layer
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[])
{
int i;
for (i = 0; i < nr; i++) {
struct buffer_head *bh = bhs[i];
if (!trylock_buffer(bh))
continue;
if (rw == WRITE) {
if (test_clear_buffer_dirty(bh)) {
bh->b_end_io = end_buffer_write_sync;
get_bh(bh);
submit_bh(WRITE, bh);
continue;
}
} else {
if (!buffer_uptodate(bh)) {
bh->b_end_io = end_buffer_read_sync;
get_bh(bh);
submit_bh(rw, bh);
continue;
}
}
unlock_buffer(bh);
}
}
int submit_bh(int rw, struct buffer_head *bh)
{
return _submit_bh(rw, bh, 0);
}
int _submit_bh(int rw, struct buffer_head *bh, unsigned long bio_flags)
{
struct bio *bio;
...
/*
* from here on down, it's all bio -- do the initial mapping,
* submit_bio -> generic_make_request may further map this bio around
*/
bio = bio_alloc(GFP_NOIO, 1);
bio->bi_sector = bh->b_blocknr * (bh->b_size >> 9);
bio->bi_bdev = bh->b_bdev;
bio->bi_io_vec[0].bv_page = bh->b_page;
bio->bi_io_vec[0].bv_len = bh->b_size;
bio->bi_io_vec[0].bv_offset = bh_offset(bh);
bio->bi_vcnt = 1;
bio->bi_size = bh->b_size;
bio->bi_end_io = end_bio_bh_io_sync;
bio->bi_private = bh;
bio->bi_flags |= bio_flags;
/* Take care of bh's that straddle the end of the device */
guard_bh_eod(rw, bio, bh);
if (buffer_meta(bh))
rw |= REQ_META;
if (buffer_prio(bh))
rw |= REQ_PRIO;
bio_get(bio);
submit_bio(rw, bio);
if (bio_flagged(bio, BIO_EOPNOTSUPP))
ret = -EOPNOTSUPP;
bio_put(bio);
return ret;
}
void submit_bio(int rw, struct bio *bio)
{
bio->bi_rw |= rw;
...
generic_make_request(bio);
}
- This comes into ‘generic_make_request()’ which is pushing the ‘bio’ into the proper ‘request_queue’ by finding out the device information
void generic_make_request(struct bio *bio)
{
struct bio_list bio_list_on_stack;
if (!generic_make_request_checks(bio))
return;
/*
* We only want one ->make_request_fn to be active at a time, else
* stack usage with stacked devices could be a problem. So use
* current->bio_list to keep a list of requests submited by a
* make_request_fn function. current->bio_list is also used as a
* flag to say if generic_make_request is currently active in this
* task or not. If it is NULL, then no make_request is active. If
* it is non-NULL, then a make_request is active, and new requests
* should be added at the tail
*/
if (current->bio_list) {
bio_list_add(current->bio_list, bio);
return;
}
/* following loop may be a bit non-obvious, and so deserves some
* explanation.
* Before entering the loop, bio->bi_next is NULL (as all callers
* ensure that) so we have a list with a single bio.
* We pretend that we have just taken it off a longer list, so
* we assign bio_list to a pointer to the bio_list_on_stack,
* thus initialising the bio_list of new bios to be
* added. ->make_request() may indeed add some more bios
* through a recursive call to generic_make_request. If it
* did, we find a non-NULL value in bio_list and re-enter the loop
* from the top. In this case we really did just take the bio
* of the top of the list (no pretending) and so remove it from
* bio_list, and call into ->make_request() again.
*/
BUG_ON(bio->bi_next);
bio_list_init(&bio_list_on_stack);
current->bio_list = &bio_list_on_stack;
do {
struct request_queue *q = bdev_get_queue(bio->bi_bdev);
if (likely(blk_queue_enter(q, false) == 0)) {
q->make_request_fn(q, bio); <---- Make a request in scheduler
blk_queue_exit(q);
bio = bio_list_pop(current->bio_list);
} else {
struct bio *bio_next = bio_list_pop(current->bio_list);
bio_io_error(bio);
bio = bio_next;
}
} while (bio);
current->bio_list = NULL; /* deactivate */
}
static inline struct request_queue *bdev_get_queue(struct block_device *bdev)
{
return bdev->bd_disk->queue; /* this is never NULL */
}
- ‘q->make_request_fn’ is calculated by finding out request_queue.
crash> dev -d
MAJOR GENDISK NAME REQUEST_QUEUE TOTAL ASYNC SYNC DRV
8 ffff883f6ce01400 sda ffff887f79950850 0 0 0 0
253 ffff887f73583000 dm-0 ffff887f6f253a30 0 0 0 0
253 ffff887f73584000 dm-1 ffff887f6f2531e0 0 0 0 0
...
crash> request_queue.make_request_fn ffff887f79950850
make_request_fn = 0xffffffff812f0110 <blk_queue_bio>
- blk_queue_bio() is merging the ‘bio’ into request_queue by getting help from evalator function which is handled in ‘elv_merge()’.
- Once it’s merged, it’ll call block devices’s ‘request_queue->request_fn()’
void blk_queue_bio(struct request_queue *q, struct bio *bio)
{
const bool sync = !!(bio->bi_rw & REQ_SYNC);
struct blk_plug *plug;
int el_ret, rw_flags, where = ELEVATOR_INSERT_SORT;
struct request *req;
...
spin_lock_irq(q->queue_lock);
el_ret = elv_merge(q, &req, bio);
...
get_rq:
...
plug = current->plug;
if (plug) {
/*
* If this is the first request added after a plug, fire
* of a plug trace.
*/
if (!request_count)
trace_block_plug(q);
else {
if (request_count >= BLK_MAX_REQUEST_COUNT) {
blk_flush_plug_list(plug, false);
trace_block_plug(q);
}
}
list_add_tail(&req->queuelist, &plug->list);
blk_account_io_start(req, true);
} else {
spin_lock_irq(q->queue_lock);
add_acct_request(q, req, where);
__blk_run_queue(q);
out_unlock:
spin_unlock_irq(q->queue_lock);
}
}
void __blk_run_queue(struct request_queue *q)
{
if (unlikely(blk_queue_stopped(q)))
return;
__blk_run_queue_uncond(q);
}
inline void __blk_run_queue_uncond(struct request_queue *q)
{
if (unlikely(blk_queue_dead(q)))
return;
/*
* Some request_fn implementations, e.g. scsi_request_fn(), unlock
* the queue lock internally. As a result multiple threads may be
* running such a request function concurrently. Keep track of the
* number of active request_fn invocations such that blk_drain_queue()
* can wait until all these request_fn calls have finished.
*/
q->request_fn_active++;
q->request_fn(q);
q->request_fn_active--;
}
crash> request_queue.request_fn ffff8810200f2ea8
request_fn = 0xffffffff813a0950 <scsi_request_fn>
- request_fn() will handle the rest of delivering operation based on the function assigned on it.
- The example block driver in the above doesn’t use ‘scsi_request_fn()’ and directly handle things in ‘sbd_request()’.
static void scsi_request_fn(struct request_queue *q)
__releases(q->queue_lock)
__acquires(q->queue_lock)
{
...
rtn = scsi_dispatch_cmd(cmd);
...
}
/**
* scsi_dispatch_command - Dispatch a command to the low-level driver.
* @cmd: command block we are dispatching.
*
* Return: nonzero return request was rejected and device's queue needs to be
* plugged.
*/
int scsi_dispatch_cmd(struct scsi_cmnd *cmd)
{
struct Scsi_Host *host = cmd->device->host;
...
rtn = host->hostt->queuecommand(host, cmd);
...
}
crash> shost -d | grep sda
0 2:0:0:0 sda 0xFFFF8810200D9800 VMware Virtual disk 1.0 11542296 11542286 ( 10) 3 -- RUNNING
crash> scsi_device.host 0xFFFF8810200D9800
host = 0xffff8810225ea000
crash> Scsi_Host.hostt 0xffff8810225ea000
hostt = 0xffffffffa01a7320 <mptspi_driver_template>
crash> scsi_host_template.queuecommand 0xffffffffa01a7320
queuecommand = 0xffffffffa01a43f0 <mptspi_qcmd> <--- block device driver's function
- Actual merging is happening in ‘elv_merge()’ by calling e->type->ops.elevator_merge_fn()
int elv_merge(struct request_queue *q, struct request **req, struct bio *bio)
{
struct elevator_queue *e = q->elevator;
...
/*
* Levels of merges:
* nomerges: No merges at all attempted
* noxmerges: Only simple one-hit cache try
* merges: All merge tries attempted
*/
...
if (e->type->ops.elevator_merge_fn)
return e->type->ops.elevator_merge_fn(q, req, bio);
return ELEVATOR_NO_MERGE;
}
crash> request_queue.elevator ffff880428608000
elevator = 0xffff880181f33800
crash> elevator_queue.type 0xffff880181f33800
type = 0xffffffff81a6ce00 <iosched_deadline>
crash> elevator_type.ops.elevator_merge_fn 0xffffffff81a6ce00
ops.elevator_merge_fn = 0xffffffff8130d3e0 <deadline_merge>,
- elevator_merge_fn for each io scheduler is shown in the below.
crash> sym iosched_cfq
ffffffff81a6cfc0 (d) iosched_cfq
crash> struct elevator_type.ops.elevator_merge_fn ffffffff81a6cfc0
ops.elevator_merge_fn = 0xffffffff8130e3f0 <cfq_merge>,
crash> sym iosched_deadline
ffffffff81a6ce00 (d) iosched_deadline
crash> struct elevator_type.ops.elevator_merge_fn ffffffff81a6ce00
ops.elevator_merge_fn = 0xffffffff8130d3e0 <deadline_merge>,
crash> sym elevator_noop
ffffffff81a6cd00 (d) elevator_noop
crash> struct elevator_type.ops.elevator_merge_fn ffffffff81a6cd00
ops.elevator_merge_fn = 0x0,
- CFQ merge: searching a proper ‘request’ using ‘redblack tree algorithm’
static int cfq_merge(struct request_queue *q, struct request **req,
struct bio *bio)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct request *__rq;
__rq = cfq_find_rq_fmerge(cfqd, bio);
if (__rq && elv_rq_merge_ok(__rq, bio)) {
*req = __rq;
return ELEVATOR_FRONT_MERGE;
}
return ELEVATOR_NO_MERGE;
}
static struct request *
cfq_find_rq_fmerge(struct cfq_data *cfqd, struct bio *bio)
{
struct task_struct *tsk = current;
struct cfq_io_cq *cic;
struct cfq_queue *cfqq;
cic = cfq_cic_lookup(cfqd, tsk->io_context);
if (!cic)
return NULL;
cfqq = cic_to_cfqq(cic, cfq_bio_sync(bio));
if (cfqq)
return elv_rb_find(&cfqq->sort_list, bio_end_sector(bio));
return NULL;
}
struct request *elv_rb_find(struct rb_root *root, sector_t sector)
{
struct rb_node *n = root->rb_node;
struct request *rq;
while (n) {
rq = rb_entry(n, struct request, rb_node);
if (sector < blk_rq_pos(rq))
n = n->rb_left;
else if (sector > blk_rq_pos(rq))
n = n->rb_right;
else
return rq;
}
return NULL;
}
- deadline merge: Doing only front merge with same direction. Otherwise, just go to block device driver
static int
deadline_merge(struct request_queue *q, struct request **req, struct bio *bio)
{
struct deadline_data *dd = q->elevator->elevator_data;
struct request *__rq;
int ret;
/*
* check for front merge
*/
if (dd->front_merges) {
sector_t sector = bio_end_sector(bio);
__rq = elv_rb_find(&dd->sort_list[bio_data_dir(bio)], sector);
if (__rq) {
...
if (elv_rq_merge_ok(__rq, bio)) {
ret = ELEVATOR_FRONT_MERGE;
goto out;
}
}
}
return ELEVATOR_NO_MERGE;
out:
*req = __rq;
return ret;
}
crash> deadline_data 0xffff88042e226d00
struct deadline_data {
sort_list = {
{
rb_node = 0x0
}, {
rb_node = 0x0
}
},
fifo_list = {
{
next = 0xffff88042e226d10,
prev = 0xffff88042e226d10
}, {
next = 0xffff88042e226d20,
prev = 0xffff88042e226d20
}
},
next_rq = {0x0, 0x0},
batching = 0x1,
last_sector = 0x809c4,
starved = 0x0,
fifo_expire = {0x1f4, 0x1388},
fifo_batch = 0x10,
writes_starved = 0x2,
front_merges = 0x1
}